Importez et journalisez votre fichier CSV de jeu de données
- Pour commencer, importez votre fichier CSV. Dans l’extrait de code suivant, remplacez le nom de fichier
iris.csvpar celui de votre fichier CSV :
- Convertissez le fichier CSV en tableau W&B afin de l’utiliser dans les tableaux de bord W&B.
- Ensuite, créez un artefact W&B et ajoutez-y le tableau :
- Enfin, démarrez un nouveau Run W&B pour suivre et journaliser vos expériences dans W&B avec
wandb.init():
wandb.init() lance un nouveau processus en arrière-plan pour journaliser des données dans un Run et synchronise les données avec wandb.ai (par défaut). Consultez des visualisations en direct dans le tableau de bord de votre Workspace W&B. L’image suivante illustre le résultat obtenu avec l’extrait de code.
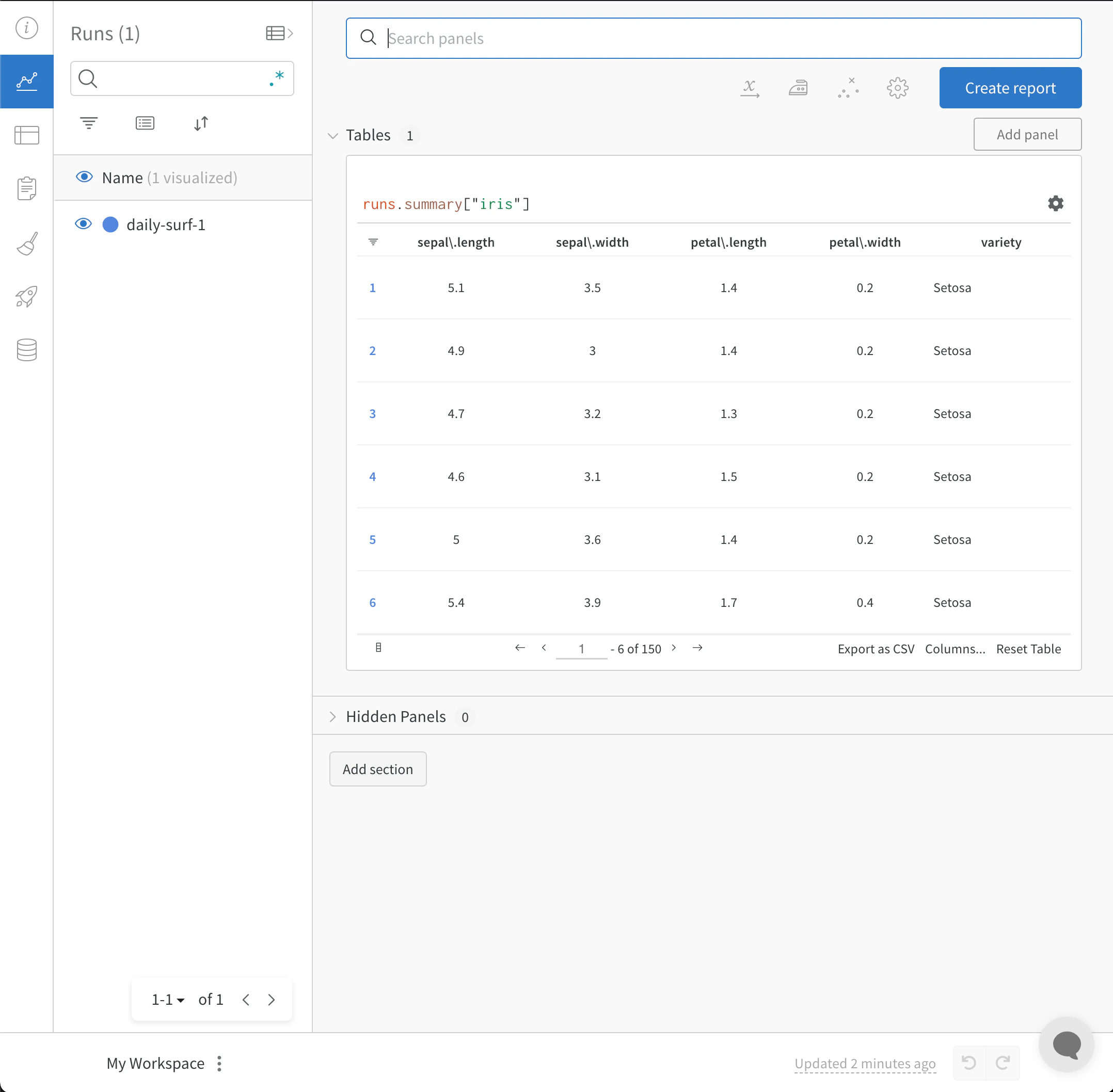
Importez et consignez votre fichier CSV d’Experiments
- Un nom pour le run de l’expérience
- Des notes initiales
- Des tags pour différencier les expériences
- Les configurations nécessaires à votre expérience (avec l’avantage supplémentaire de pouvoir utiliser notre fonctionnalité de réglage des hyperparamètres Sweeps).
| Expérience | Nom du modèle | Notes | Tags | Nb de couches | Acc. finale entraînement | Acc. finale val. | Pertes d’entraînement |
|---|---|---|---|---|---|---|---|
| Expérience 1 | mnist-300-layers | Surapprentissage beaucoup trop important sur les données d’entraînement | [latest] | 300 | 0.99 | 0.90 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Expérience 2 | mnist-250-layers | Meilleur modèle actuel | [prod, best] | 250 | 0.95 | 0.96 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Expérience 3 | mnist-200-layers | Résultats inférieurs à ceux du modèle de référence. Débogage nécessaire | [debug] | 200 | 0.76 | 0.70 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| … | … | … | … | … | … | … | |
| Expérience N | mnist-X-layers | NOTES | … | … | … | … | […, …] |
- Pour commencer, lisez votre fichier CSV et convertissez-le en DataFrame Pandas. Remplacez
"experiments.csv"par le nom de votre fichier CSV :
-
Ensuite, démarrez une nouvelle exécution W&B pour suivre et consigner vos données dans W&B à l’aide de
wandb.init():
run.log() pour ce faire :
define_metric. Cet exemple ajoute les métriques de synthèse à notre run avec run.summary.update():