1. データを W&B にログする
wandb.Table() でログします。ログする各キーについて、データポイントは最大 10,000 件までにすることを推奨します。
2. クエリを作成する
+ ボタンをクリックして新しいパネルを追加し、Custom Chart を選択します。ワークスペースを開きながら進めることもできます。

クエリを追加する
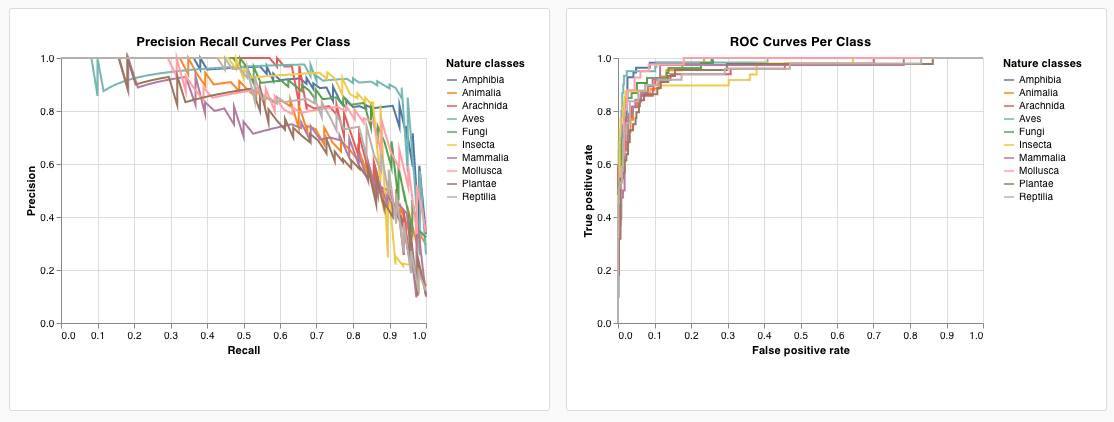
summaryをクリックし、historyTableを選択して、run の履歴からデータを取得する新しいクエリを設定します。wandb.Table()をログしたキーを入力します。上記のコードスニペットではmy_custom_tableです。サンプルノートブック では、キーはpr_curveとroc_curveです。
Vega フィールドを設定する
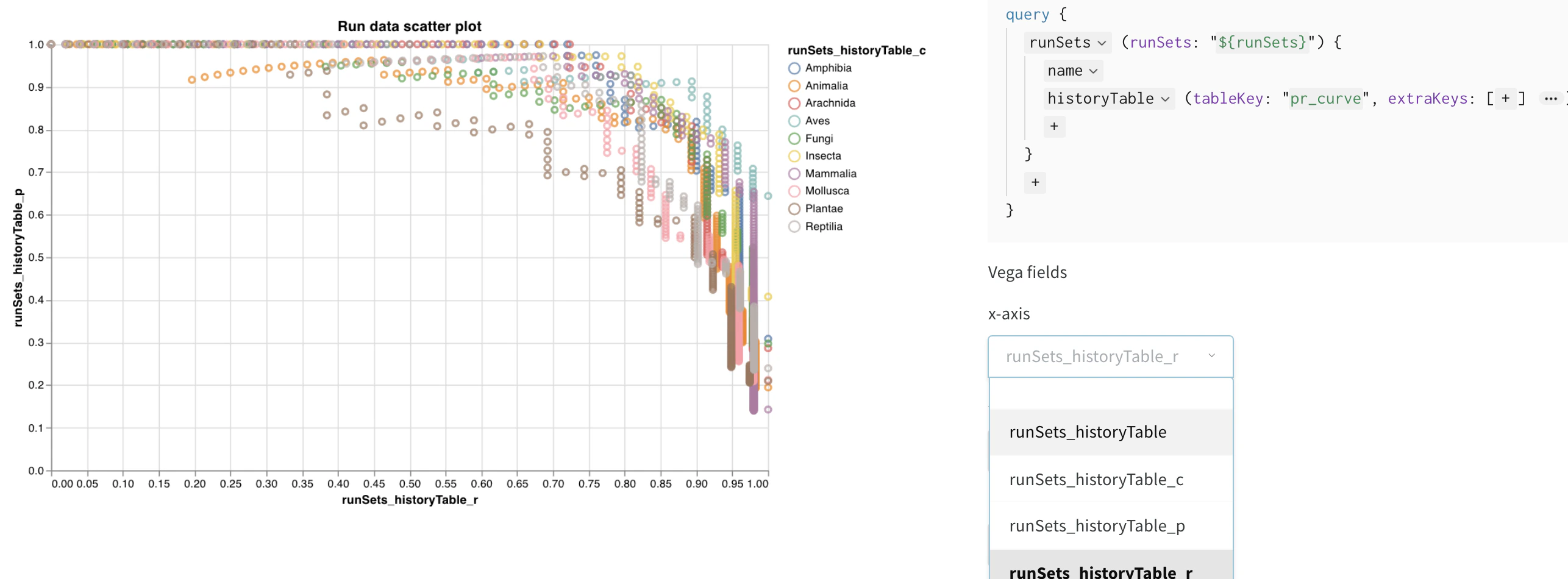
- x-axis: runSets_historyTable_r (再現率)
- y-axis: runSets_historyTable_p (適合率)
- color: runSets_historyTable_c (クラスラベル)
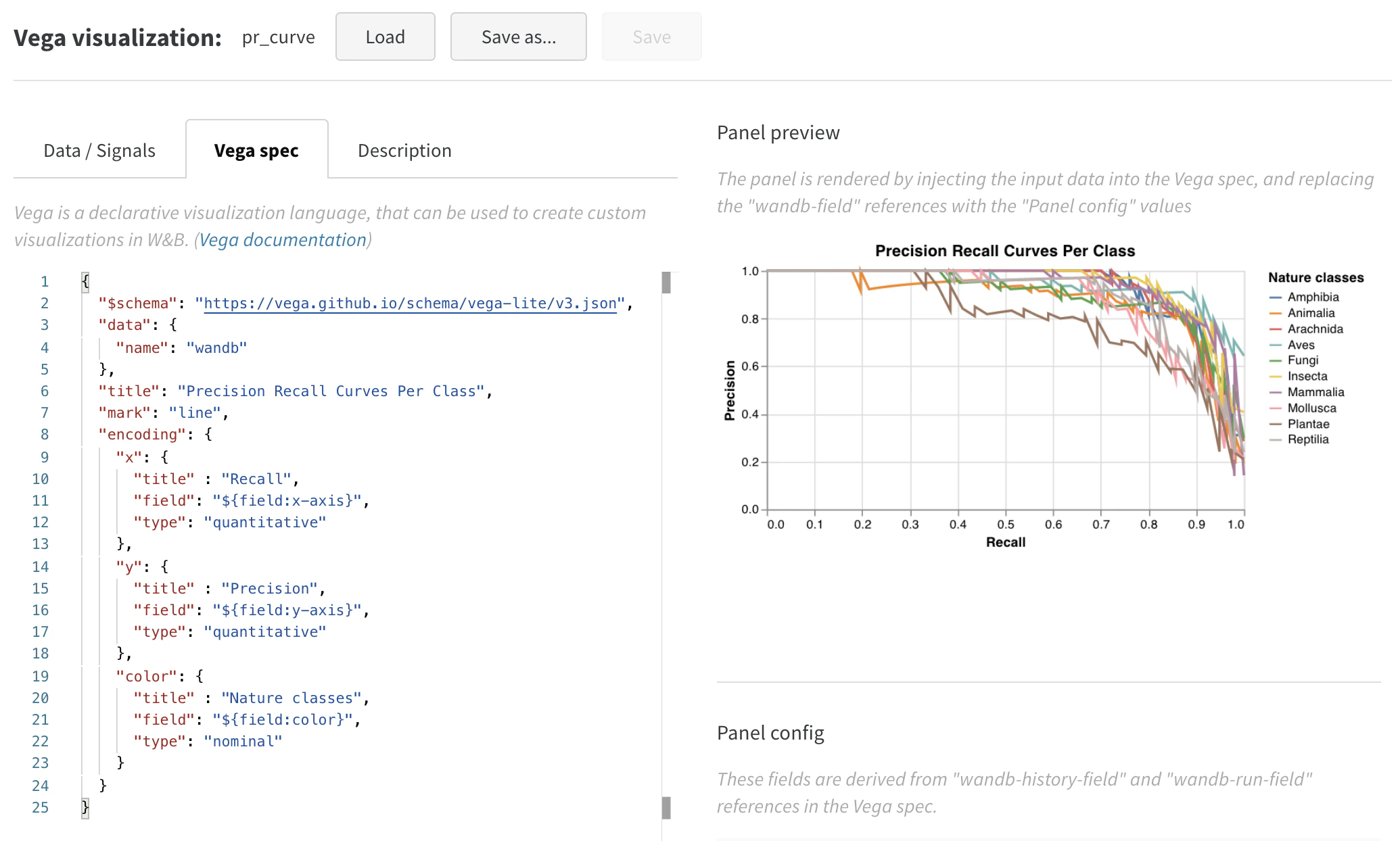
3. チャートをカスタマイズする

- プロット、凡例、x軸、y軸にタイトルを追加する (各フィールドの
titleを設定) markの値をpointからlineに変更する- 未使用の
sizeフィールドを削除する
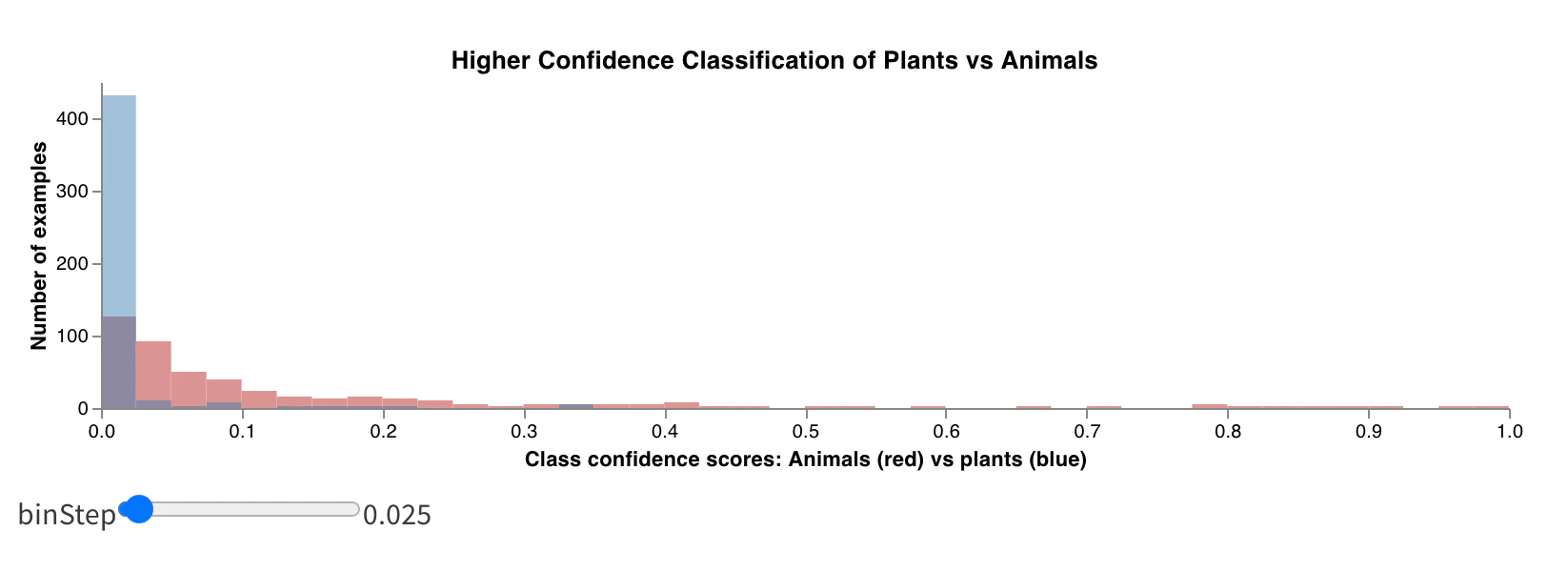
おまけ: 複合ヒストグラム
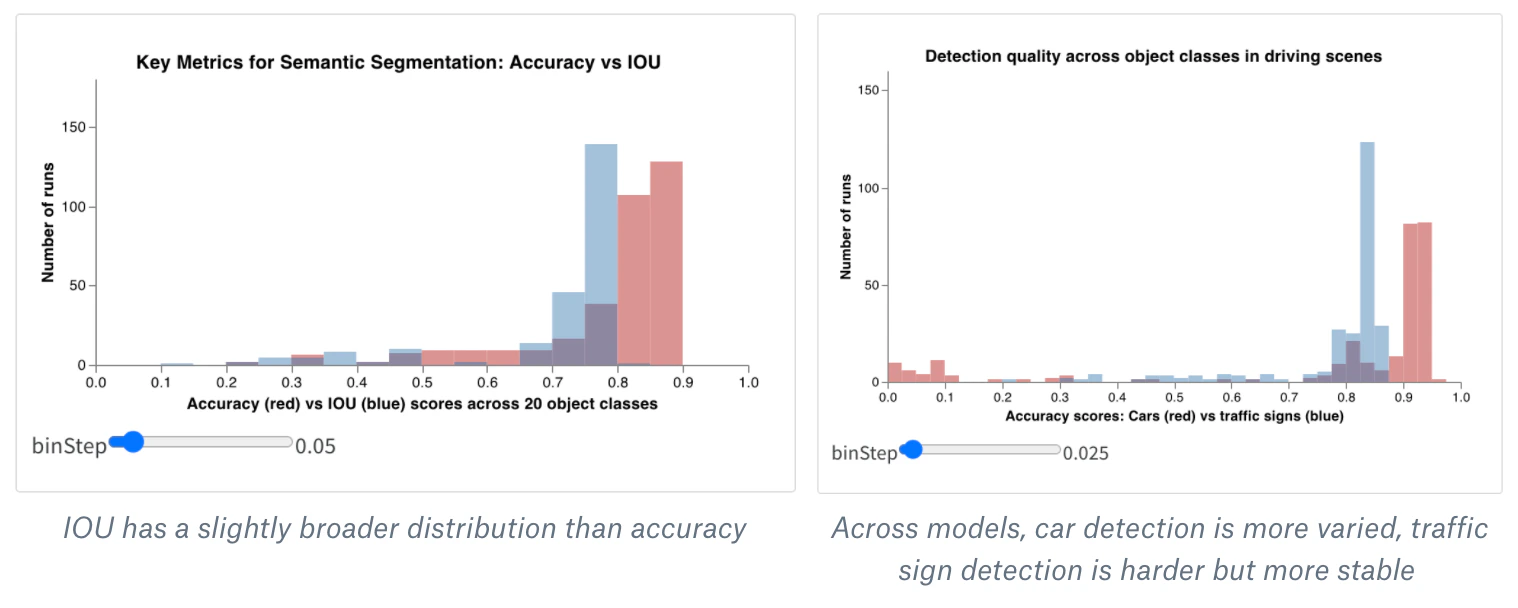
- Workspace または Report で新しい Custom Chart パネルを作成します (「Custom Chart」可視化を追加します) 。右上の「Edit」ボタンをクリックすると、任意の組み込みパネルタイプをベースに Vega spec を編集できます。
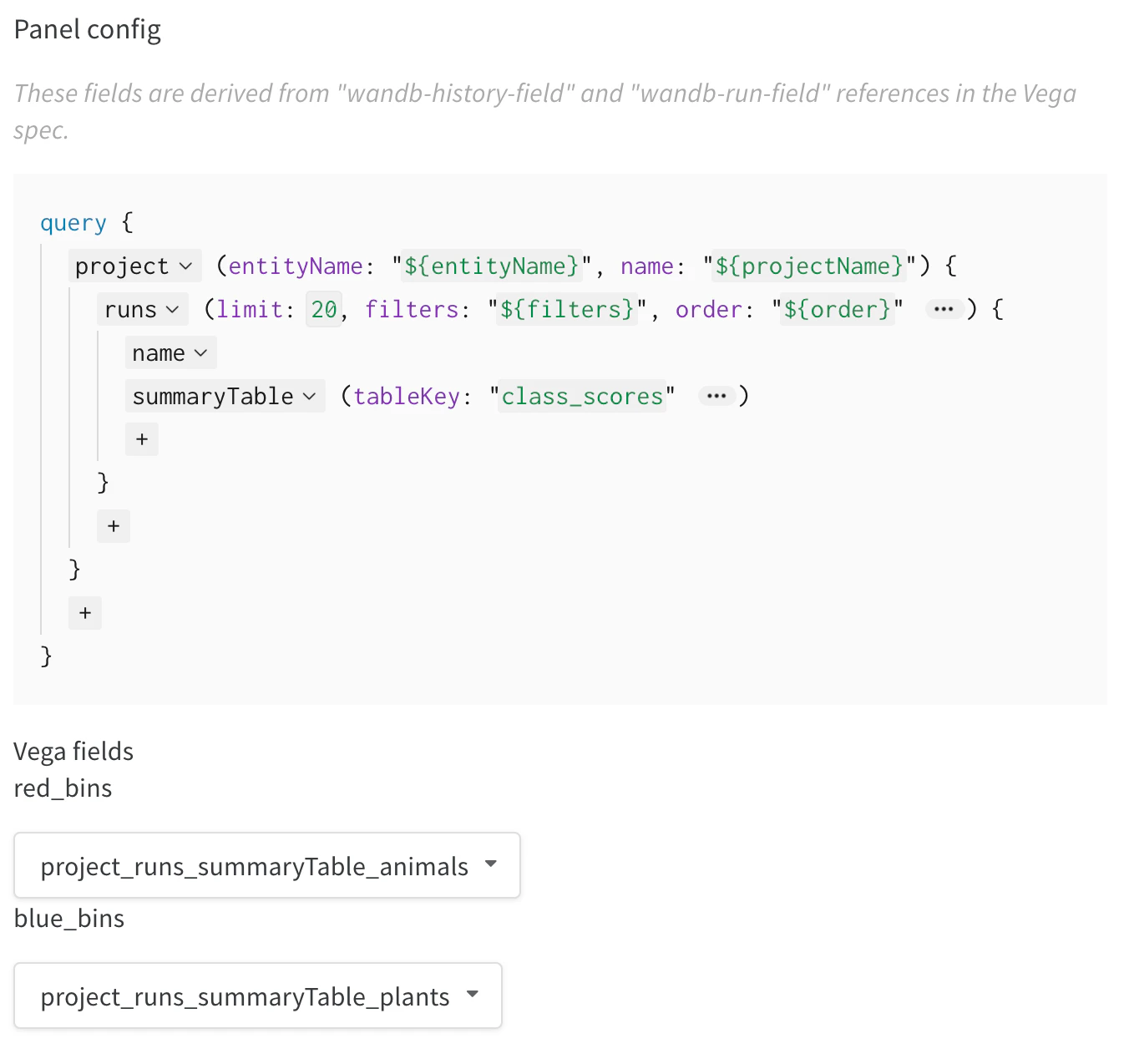
- その組み込みの Vega spec を、私の Vega による複合ヒストグラム用 MVP コード に置き換えます。メインタイトル、軸タイトル、入力ドメイン、そのほかの詳細は、この Vega spec を Vega 構文を使って 直接変更できます (colors を変えたり、3つ目のヒストグラムを追加したりすることもできます :)) 。
- 右側のクエリを編集して、wandb のログから正しいデータを読み込みます。
summaryTableフィールドを追加し、対応するtableKeyをclass_scoresに設定して、run によってログされたwandb.Tableを取得します。これにより、class_scoresとしてログされたwandb.Tableの列を使って、ドロップダウンメニューから2つのヒストグラムのビンセット (red_binsとblue_bins) を設定できるようになります。私の例では、赤のビンにanimalクラスの予測スコア、青のビンにplantを選びました。 - プレビュー表示されるプロットに満足するまで、Vega spec とクエリを引き続き調整できます。完了したら、上部の Save as をクリックし、再利用できるようにカスタムプロットに名前を付けます。次に Apply from panel library をクリックして、プロットを完成させます。