このノートブックで学ぶこと
インストール、インポート、ログイン
Step 0: W&B をインストール
wandb は pip を使って簡単にインストールできます。
Step 1: W&B をインポートしてログイン
実験とパイプラインを定義する
wandb.init() でメタデータとハイパーパラメーターをトラッキングする
config 辞書
(または同様のオブジェクト)
に保存し、
必要に応じて参照するのが一般的なワークフローです。
この例では、変化させるハイパーパラメーターはごく一部だけで、
残りはコードに直接書いています。
ただし、モデルのどの部分でも config に含めることができます。
また、いくつかのメタデータも含めています。使用しているのは MNIST データセットと畳み込み
アーキテクチャです。後で、たとえば
同じプロジェクト内で CIFAR 上の全結合アーキテクチャを扱うことになった場合でも、
これによって run を区別しやすくなります。
- まず、モデルとそれに対応するデータ、オプティマイザを
makeし、 - 次にモデルを
trainして、 - 最後に
testし、トレーニングの結果を確認します。
wandb.init() のコンテキスト内で行われることです。
この関数を呼び出すと、
コードと W&B のサーバーの間の通信が確立されます。
config 辞書を wandb.init() に渡すと、
その情報はすぐにすべてログされるため、
実験で使用するよう設定した
ハイパーパラメーターの値をいつでも把握できます。
選択してログした値が常に実際にモデルで使われる値になるよう、
オブジェクトの run.config コピーを使用することをおすすめします。
いくつか例を示すので、以下の make の定義を確認してください。
補足: W&B ではコードを別プロセスで実行するようにしているため、
こちら側で問題が発生しても
(たとえば巨大な海の怪物がデータセンターを襲ったとしても)
あなたのコードがクラッシュすることはありません。
問題が解決したら、たとえばクラーケンが深海に戻ったあとで、
wandb sync を使ってデータをログできます。
データの読み込みとモデルを定義する
wandb を
使わない場合と変わらないため、
ここでは詳しくは扱いません。
wandb を使ってもここは特に変わらないので、
標準的な ConvNet アーキテクチャをそのまま使います。
いろいろ試したり、実験してみたりすることをためらわないでください —
結果はすべて wandb.ai にログされます。
トレーニングロジックを定義する
model_pipeline を進めていき、次は train をどのように行うかを指定します。
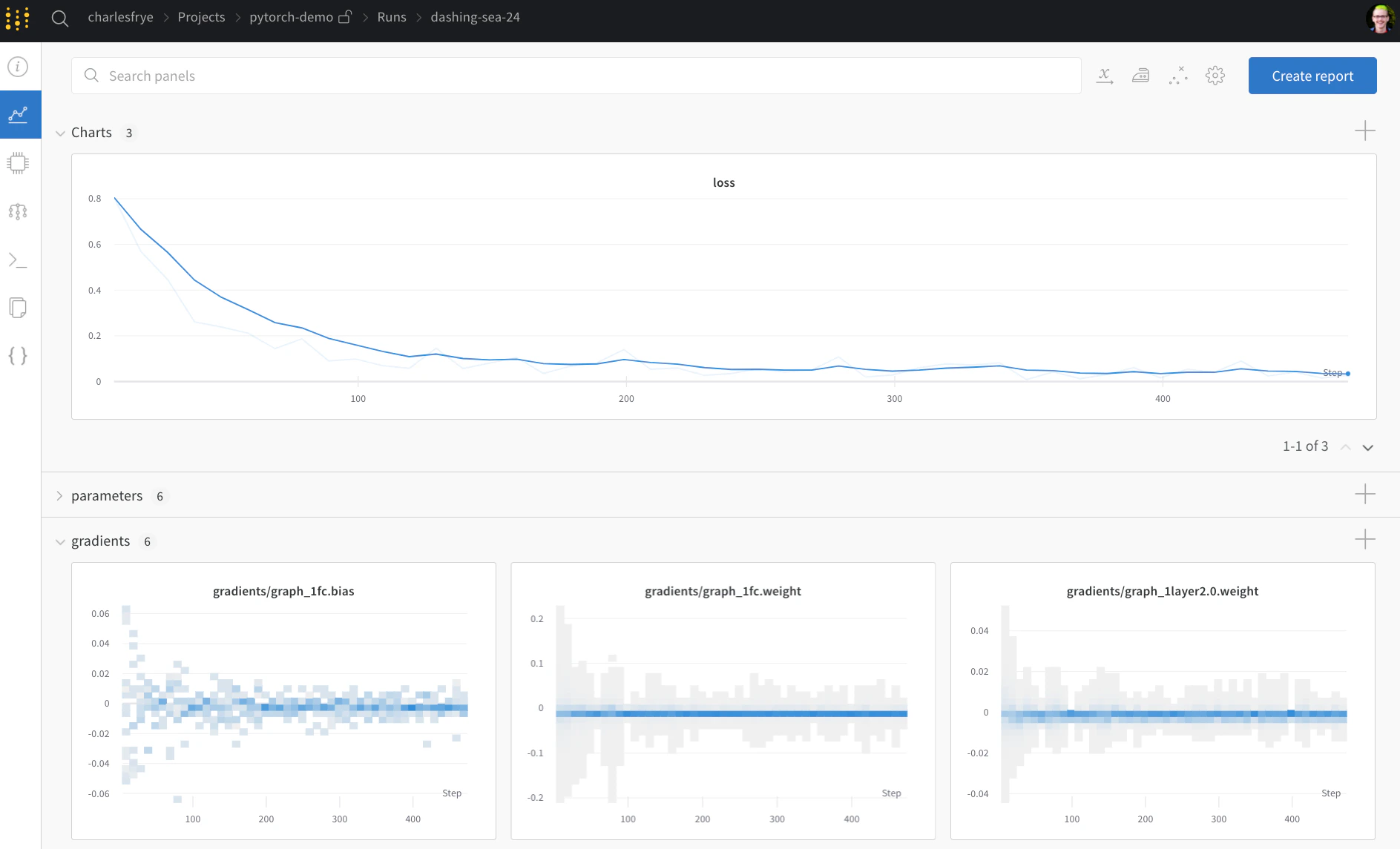
ここでは、wandb の 2 つの関数 watch と log を使います。
勾配は run.watch() でトラッキングし、それ以外はすべて run.log() でログする
run.watch() は、トレーニング中 log_freq step ごとに、
モデルの勾配とパラメーターをログします。
必要なのは、トレーニングを始める前にこれを呼び出すだけです。
それ以外のトレーニングコードはそのままです。
エポックとバッチを繰り返し処理し、
フォワードパスとバックワードパスを実行して
optimizer を適用します。
run.log() に渡します。
run.log() には、キーが文字列の辞書を渡します。
これらの文字列は、ログするオブジェクトを識別する名前で、対応する値がその内容になります。
さらに、トレーニングのどの step にいるかを任意でログすることもできます。
補足: 私は、モデルがこれまでに見たサンプル数を使うのが好きです。
そのほうが、バッチサイズが違っても比較しやすいからです。
もちろん、単純な step 数やバッチ数を使用してもかまいません。トレーニング run が長い場合は、epoch ごとにログするのも合理的です。
テスト方法を定義する
(任意) run.save() を呼び出す
export します。
そのファイル名を run.save() に渡すことで、モデルのパラメーターが
W&B のサーバーにも保存されます。これで、どの .h5 や .pb が
どのトレーニング run に対応しているのか分からなくなることはありません。
モデルの保存、バージョン管理、配布に関する、より高度な wandb の機能については、
Artifacts tools を参照してください。
トレーニングを実行し、wandb.ai でメトリクスをライブで確認する
- Charts。ここでは、トレーニング全体を通してモデルの勾配、パラメーターの値、損失がログされます
- System。ここには、ディスク I/O 使用率、CPU と GPU のメトリクス (温度が急上昇する様子にも注目です) など、さまざまなシステムメトリクスが含まれます
- Logs。ここには、トレーニング中に標準出力に出力された内容のコピーがあります
- Files。ここでは、トレーニング完了後に
model.onnxをクリックすると、Netron model viewer でネットワークを表示できます。
with wandb.init() ブロックを抜けると、
セルの出力にも結果の概要が表示されます。
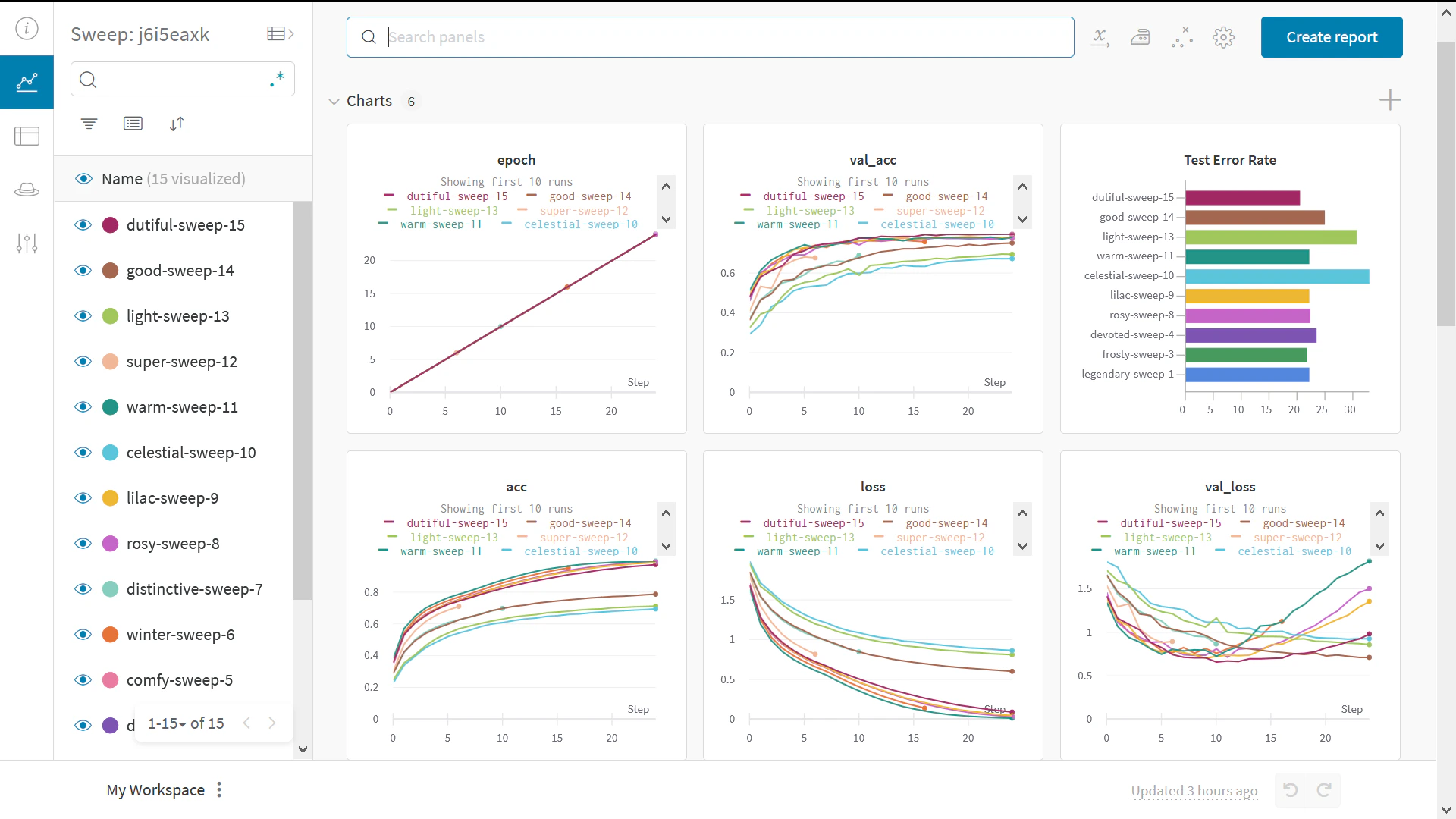
Sweeps でハイパーパラメーターを試す
- sweep を定義する: 検索対象のパラメーター、検索戦略、最適化メトリクスなどを指定する辞書または YAML ファイル を作成します。
-
sweep を初期化する:
sweep_id = wandb.sweep(sweep_config) -
sweep agent を実行する:
wandb.agent(sweep_id, function=train)