- 単一のプロセスをトラッキングする: rank 0 のプロセス (“leader” または “coordinator” とも呼ばれます) をW&Bでトラッキングします。これは、PyTorch Distributed Data Parallel (DDP) Class を使用した分散トレーニング実験のログで一般的な方法です。
- 複数のプロセスをトラッキングする: 複数のプロセスをトラッキングする場合は、次のいずれかの方法を使用できます。
- 各プロセスを、プロセスごとに1つの run を使って個別にトラッキングします。必要に応じて、W&B App UI でまとめてグループ化することもできます。
- すべてのプロセスを単一の run にトラッキングします。
単一プロセスをトラッキングする
wandb.init() を使用して W&B run を初期化し、その run に実験データをログします (wandb.Run.log()) 。
次の Python サンプルスクリプト (log-ddp.py) は、PyTorch DDP を使用して 1 台のマシン上の 2 つの GPU でメトリクスをトラッキングする方法の一例を示しています。PyTorch DDP (torch.nn の DistributedDataParallel) は、分散トレーニングで広く使われているライブラリです。基本的な考え方はどの分散トレーニング構成にも当てはまりますが、実装は異なる場合があります。
この Python スクリプトでは、次のことを行います。
torch.distributed.launchを使用して複数のプロセスを起動します。--local_rankコマンドライン引数で rank を確認します。- rank が 0 に設定されている場合、
train()関数内で条件付きでwandbをログする設定します。
複数のプロセスをトラッキングする
- 各プロセスごとに run を作成して、各プロセスを個別にトラッキングする。
- すべてのプロセスを 1 つの run にトラッキングする。
各プロセスを個別にトラッキングする
wandb.Run.finish() を呼び出して、run が完了したことを示します。
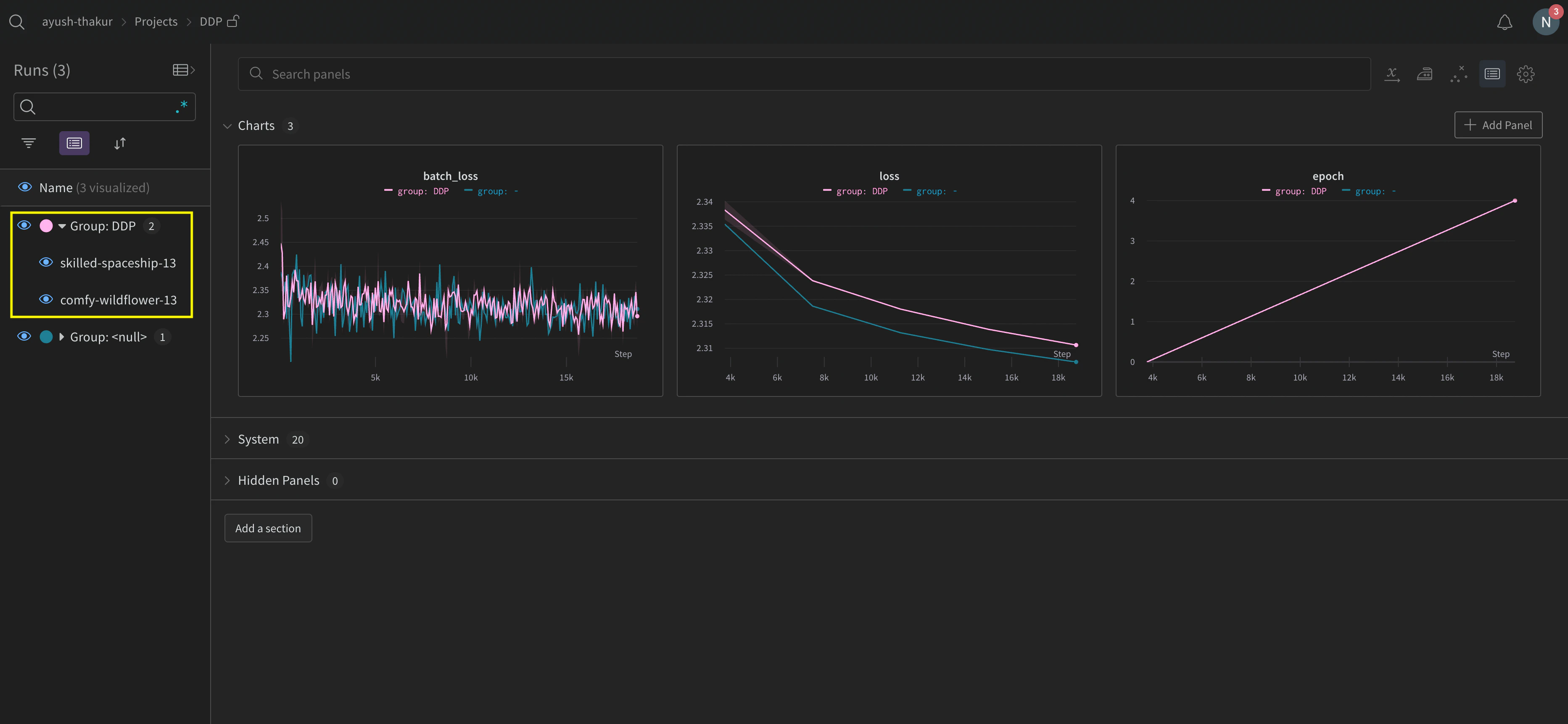
複数の実験にまたがる run の管理は難しいことがあります。これを軽減するには、W&B の初期化時に group パラメーターに値を指定し (wandb.init(group='group-name')) 、どの run がどの実験に属するかを追跡できるようにします。実験内でトレーニングおよび評価の W&B Runs を追跡する方法の詳細については、Group Runsを参照してください。
個々のプロセスからのメトリクスをトラッキングしたい場合は、この方法を使用してください。代表的な例としては、各ノード上のデータと予測 (データ分散のデバッグ用) や、メインノード以外での個々のバッチのメトリクスがあります。なお、この方法は、すべてのノードからシステムメトリクスを取得したり、メインノードで利用可能な要約統計を取得したりするためには必要ありません。
group パラメーターを設定する方法を示しています。
分散 run を整理する
job_type パラメーター (wandb.init(job_type='type-name')) を設定すると、各ノードをその役割に応じて分類できます。たとえば、全体を制御するメインノードと、結果を報告する複数のワーカーノードで構成される場合があります。メインノードでは job_type を main に、結果を報告するワーカーノードでは worker に設定できます。
job_type を設定したら、Workspace で 保存済みビュー を作成して runs を整理できます。右上の action () メニューをクリックし、Save as new view をクリックします。
たとえば、次のような保存済みビューを作成できます。
- Default view: worker ノードを除外してノイズを減らす
-
フィルター をクリックし、Job Type を
workerに設定します。 - レポート用ノードのみが表示されます
-
Debug view: トラブルシューティングのために worker ノードに絞り込む
- フィルター をクリックし、Job Type を
==workerに設定し、State をINcrashedに設定します。 - クラッシュした worker ノード、またはエラー状態の worker ノードのみが表示されます
- フィルター をクリックし、Job Type を
-
All nodes view: すべてをまとめて表示する
- フィルターなし
- 全体を監視する際に便利です
-
フィルター をクリックし、Job Type を
すべてのプロセスを単一の run にトラッキングする
要件複数のプロセスを単一の run にトラッキングするには、以下が必要です。
-
W&B Python SDK バージョン
v0.19.9以降 - W&B Server v0.68 以降
wandb.init() を使って W&B run を初期化します。settings パラメーターに wandb.Settings オブジェクト (wandb.init(settings=wandb.Settings()) を渡し、以下を設定します。
- 共有モードを有効にするため、
modeパラメーターを"shared"に設定します。 x_labelに一意のラベルを設定します。x_labelに指定した値は、ログおよび W&B App UI のシステムメトリクスで、データがどのノードから送られてきたかを識別するために使用されます。指定しない場合、W&B はホスト名とランダムなハッシュを使ってラベルを作成します。- これがプライマリノードであることを示すため、
x_primaryパラメーターをTrueに設定します。 - 必要に応じて、W&B がどの GPU のメトリクスをトラッキングするかを指定するため、GPU インデックスのリスト ([0,1,2]) を
x_stats_gpu_device_idsに指定します。リストを指定しない場合、W&B はそのマシン上のすべての GPU のメトリクスをトラッキングします。
x_primary=True は、プライマリノードとワーカーノードを区別するための設定です。設定ファイルやテレメトリーなど、ノード間で共有されるファイルを upload できるのはプライマリノードだけです。ワーカーノードはこれらのファイルを upload しません。wandb.init() で W&B run を初期化し、以下を指定します。
settingsパラメーターにwandb.Settingsオブジェクト (wandb.init(settings=wandb.Settings()) を渡し、次を設定します。- 共有モードを有効にするため、
modeパラメーターを"shared"に設定します。 x_labelに一意のラベルを設定します。x_labelに指定した値は、ログおよび W&B App UI のシステムメトリクスで、データがどのノードから送られてきたかを識別するために使用されます。指定しない場合、W&B はホスト名とランダムなハッシュを使ってラベルを作成します。- これがワーカーノードであることを示すため、
x_primaryパラメーターをFalseに設定します。
- 共有モードを有効にするため、
- プライマリノードで使用している run ID を
idパラメーターに渡します。 - 必要に応じて、
x_update_finish_stateをFalseに設定します。これにより、非プライマリノードが run の状態 を早い段階でfinishedに更新してしまうのを防ぎ、run の状態を一貫してプライマリノードで管理できます。
- すべてのノードで同じ entity とプロジェクトを使用してください。これにより、正しい run ID を確実に見つけやすくなります。
- プライマリノードの run ID を設定するために、各ワーカーノードで環境変数を定義することを検討してください。
GKE 上のマルチノードかつマルチ GPU の Kubernetes クラスターでモデルを
トレーニングする方法をエンドツーエンドで示した例については、Distributed Training with Shared Mode report を参照してください。
- run を含む project にアクセスします。
- プロジェクトのサイドバーで Runs タブをクリックします。
- 表示したい run をクリックします。
- プロジェクトのサイドバーで Logs タブをクリックします。
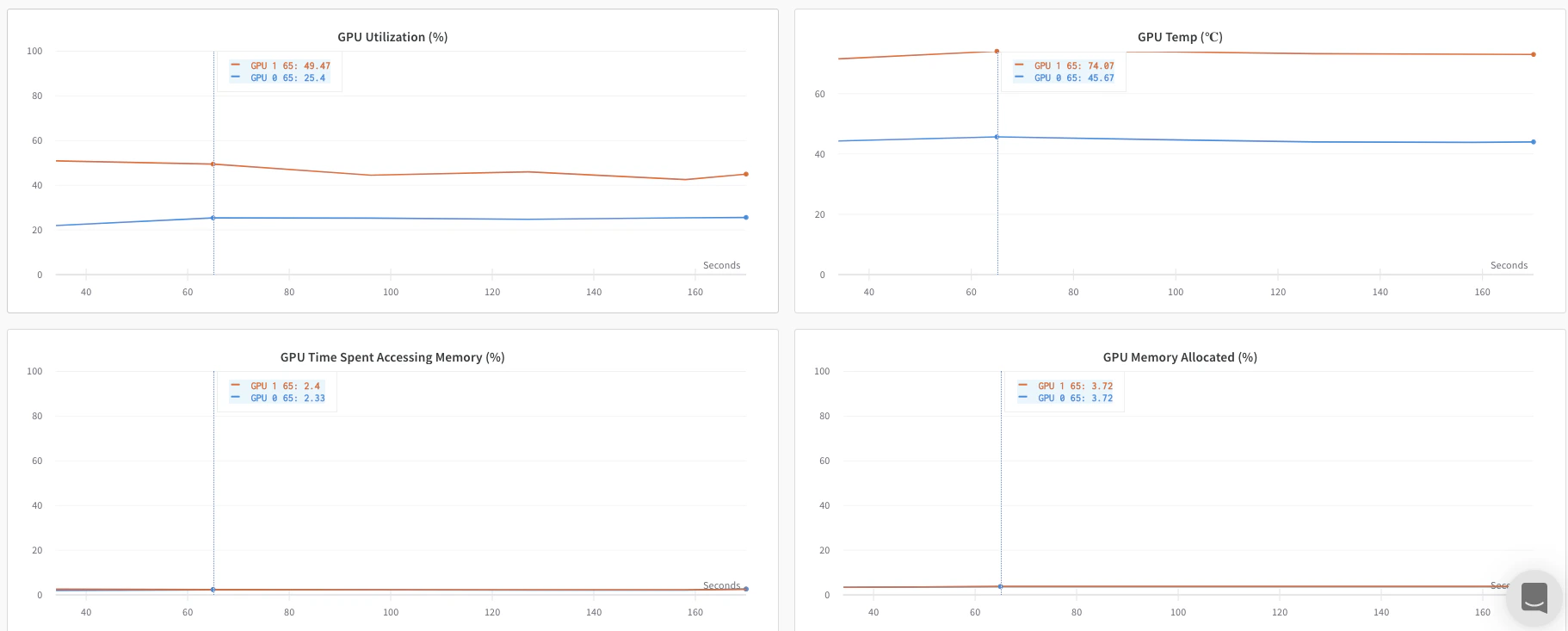
x_label に指定したラベルに基づいてコンソールログをフィルターできます。たとえば、次の画像は、rank0、rank1、rank2、rank3、rank4、rank5、rank6 の各値を x_label に指定した場合に、コンソールログのフィルターに使用できるオプションを示しています。`
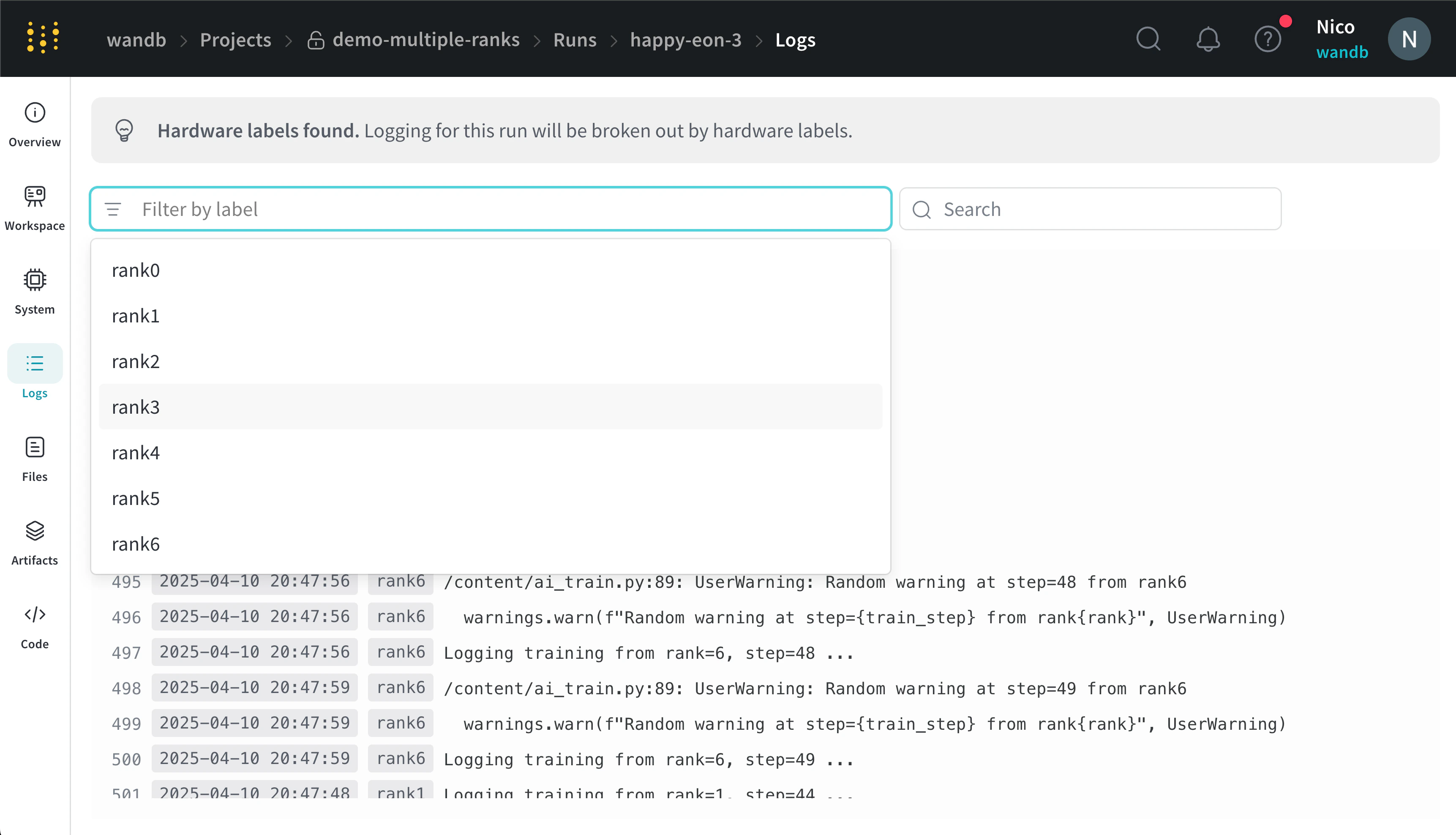
x_label パラメーターで指定する一意のラベル (rank_0、rank_1、rank_2) があります。
使用例
プロセスの生成
wandb.setup() method を使用します。
トラブルシューティング
- トレーニング開始時にハングする - 分散トレーニングのマルチプロセッシングと
wandbのマルチプロセッシングが干渉すると、wandbプロセスがハングすることがあります。 - トレーニング終了時にハングする -
wandbプロセスがいつ終了すべきかを認識できない場合、トレーニング ジョブがハングすることがあります。Python スクリプトの最後でwandb.Run.finish()API を呼び出して、run が終了したことを W&B に通知してください。wandb.Run.finish()API はデータのアップロードを完了し、W&B を終了させます。 W&B では、分散ジョブの信頼性を向上させるためにwandb serviceコマンドを使用することを推奨しています。前述の 2 つのトレーニングの問題は、wandb service を利用できないバージョンの W&B SDK でよく見られます。
W&B Service を有効にする
W&B SDK 0.13.0 以降
0.13.0 以降では、W&B Service はデフォルトで有効です。
W&B SDK 0.12.5 以降
wandb.require() method を使用し、文字列 "service" を渡してください。
WANDB_START_METHOD 環境変数を "thread" に設定します。