Full fidelity
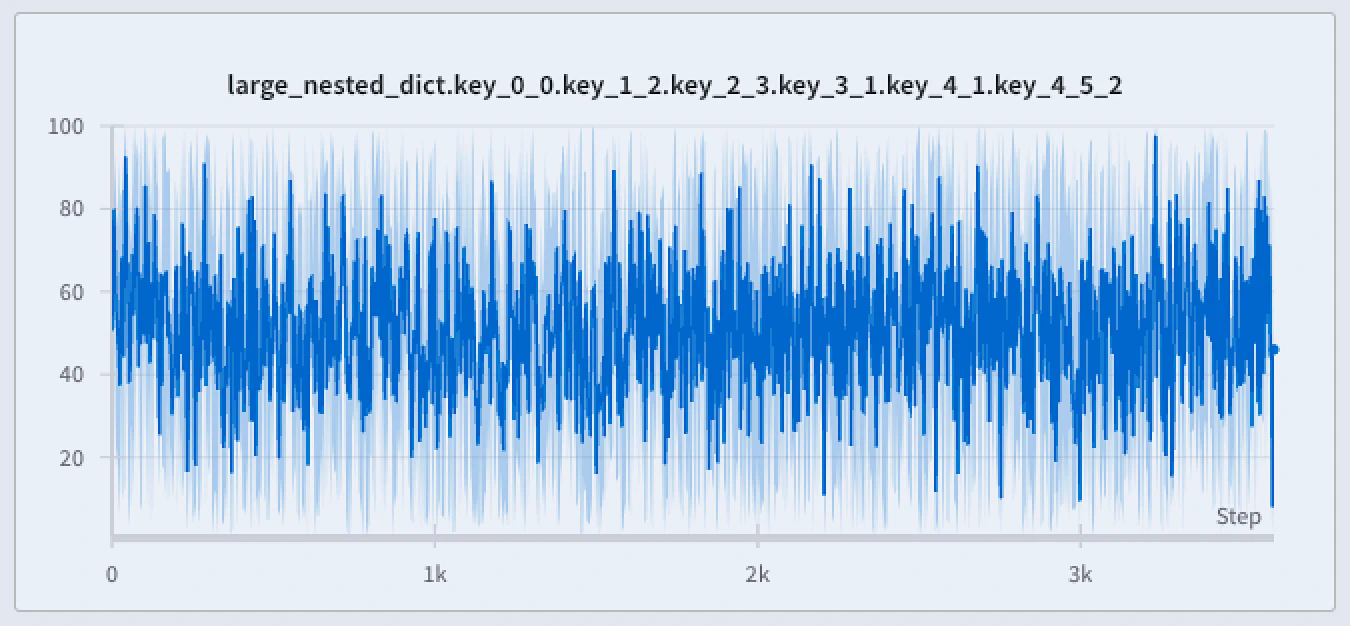
- 극값과 스파이크 보존: 데이터의 극값과 스파이크를 유지합니다.
- 최솟값 및 최댓값 포인트의 render 방식 설정: W&B App을 사용해 극값(min/max)을 음영 영역으로 표시할지 대화형으로 결정할 수 있습니다.
- 데이터 fidelity를 유지하면서 데이터 탐색: 특정 데이터 포인트로 확대하면 W&B가 x축 버킷 크기를 다시 계산합니다. 이를 통해 정확도를 잃지 않고 데이터를 탐색할 수 있습니다. 이전에 계산한 aggregation은 캐싱되어 로드 시간을 줄여 주며, 특히 큰 데이터셋을 탐색할 때 유용합니다.
full fidelity 활성화
- 워크스페이스의 모든 차트
- 워크스페이스의 개별 차트
- 워크스페이스로 이동합니다.
- 화면 오른쪽 상단에서 Add panels 버튼 왼쪽에 있는 톱니바퀴 아이콘을 선택합니다.
- 표시되는 UI 슬라이더에서 선형 플롯을 선택합니다.
- 포인트 집계 섹션에서 Full fidelity를 선택합니다.
- 스무딩 알고리즘과 설정을 구성합니다.
- 집계를 평균, 최소, 또는 최대로 설정합니다.
- 적용을 클릭합니다.
음영 설정
- 최소/최대: 각 X축 지점에서 최솟값과 최댓값 사이 영역에 음영을 표시합니다. 음영 영역은 각 버킷에서 가장 낮은 값부터 가장 높은 값까지의 모든 지점을 보여줍니다. 여기서 x_1, x_2, \ldots, x_n는 주어진 버킷의 값입니다.
- 표준편차: 각 X축 지점에서 표준편차를 사용해 값의 변동성을 계산하고, 그 결과 영역에 음영을 표시합니다.
- 표준오차: 각 X축 지점에서 표준편차를 표본 크기의 제곱근으로 나누어 표본오차의 가능성을 계산합니다.
- 없음: 음영을 표시하지 않습니다(기본값).
- 워크스페이스로 이동합니다.
- 선형 플롯 위에 마우스를 올린 다음 톱니바퀴 아이콘을 클릭합니다.
- Data 탭에서 필요하면 포인트 집계를 Full fidelity로 설정한 다음, 스무딩 알고리즘을 구성합니다.
- Grouping 탭에서 Group runs를 켭니다. 필요에 따라 Group by를 run 속성으로 설정합니다.
- Agg를 Mean(기본값), Min, 또는 Max로 설정합니다.
- Range를 Min/Max, Std Dev, Std Err, 또는 None으로 설정합니다.
- Apply를 클릭합니다.
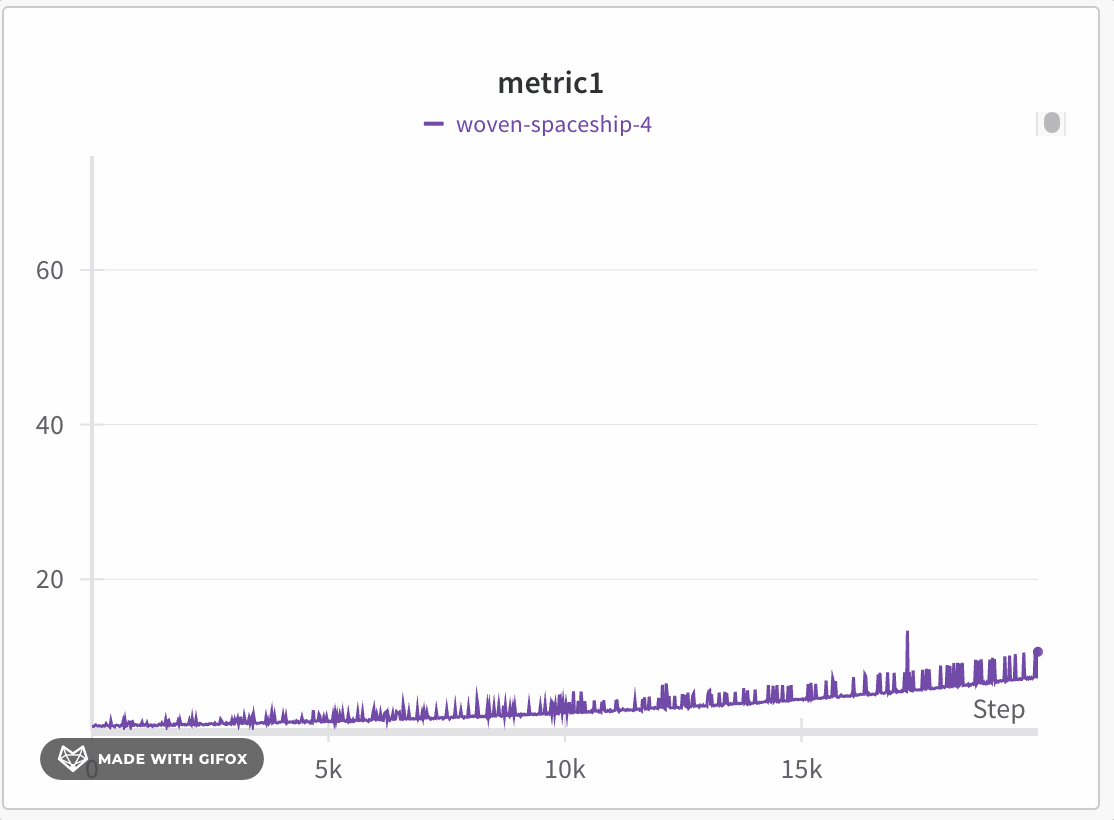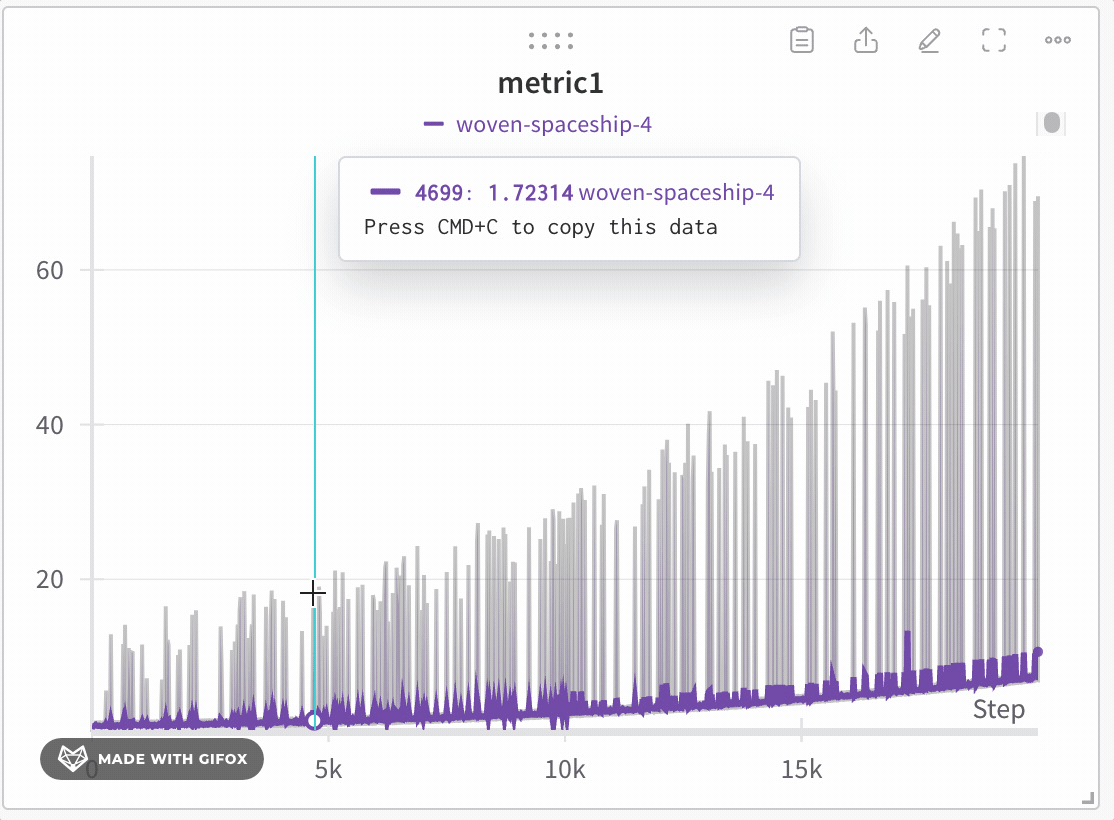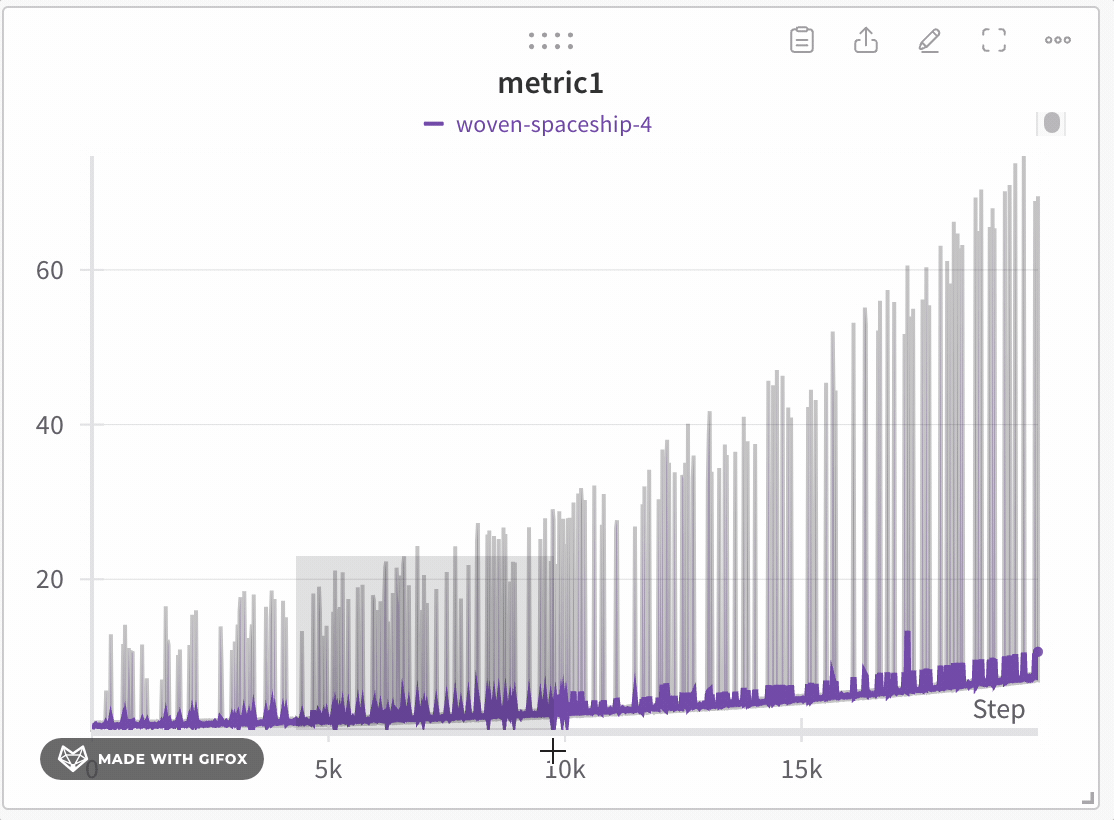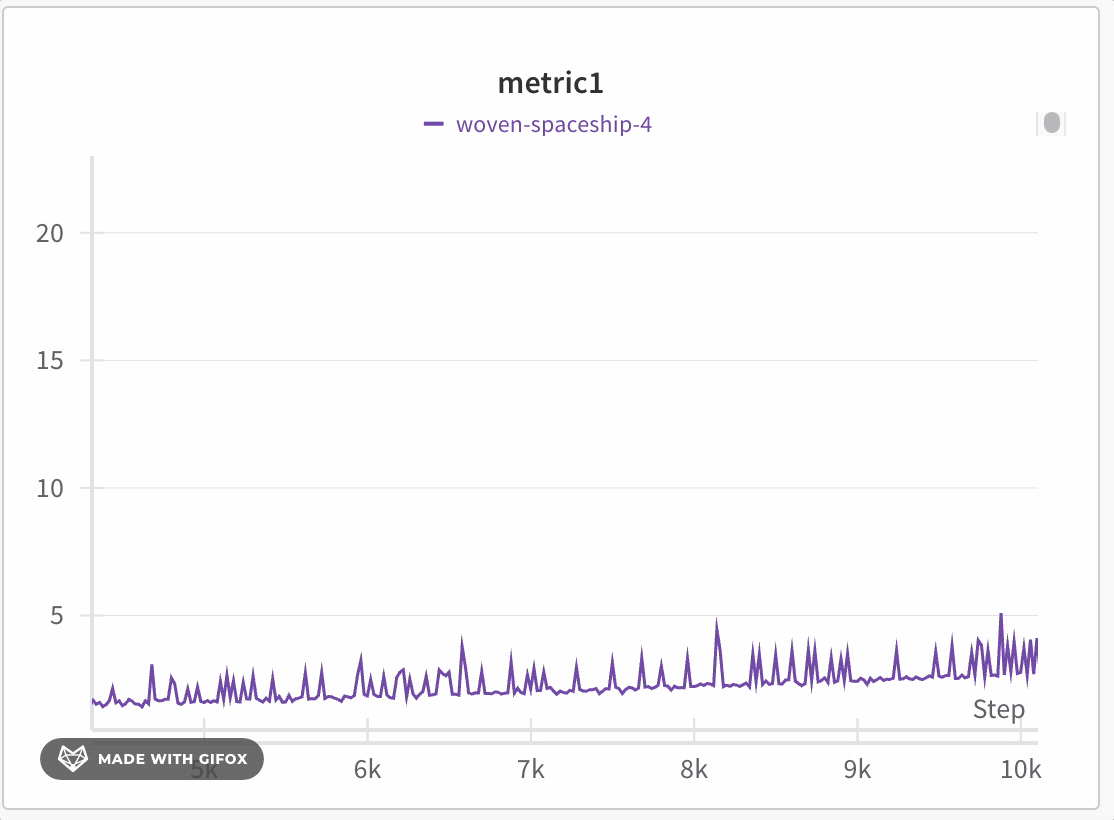
데이터 충실성을 유지한 채 데이터 탐색하기
- 최소값: 해당 버킷의 가장 낮은 값입니다(음영 처리에 사용).
- 최대값: 해당 버킷의 가장 높은 값입니다(음영 처리에 사용).
- 선 값: 해당 버킷의 마지막 값으로, 선을 그리는 데 사용됩니다.
- W&B 프로젝트로 이동합니다
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다
- 필요에 따라 워크스페이스에 선형 플롯 패널을 추가하거나 기존 선형 플롯 패널로 이동합니다.
- 클릭한 상태로 드래그하여 확대할 특정 영역을 선택합니다.
선형 플롯 그룹화 및 표현식Line Plot Grouping을 사용하면 W&B는 선택한 모드에 따라 다음을 적용합니다:
- 비윈도우 샘플링(그룹화): x축에서 run 간 포인트를 정렬합니다. 여러 포인트가 동일한 x값을 공유하면 평균을 계산하고, 그렇지 않으면 개별 포인트로 표시됩니다.
- 윈도우 샘플링(그룹화 및 표현식): x축을 250개 버킷 또는 가장 긴 선의 포인트 수 중 더 작은 값 기준으로 나눕니다. W&B는 각 버킷 내 포인트의 평균을 계산합니다.
- Full fidelity(그룹화 및 표현식): 비윈도우 샘플링과 유사하지만, 성능과 세부 표현의 균형을 위해 run당 최대 500개 포인트를 가져옵니다.
랜덤 샘플링
랜덤 샘플링 활성화
- 워크스페이스의 모든 차트
- 워크스페이스의 개별 차트
- W&B 프로젝트로 이동합니다
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다
- 화면 오른쪽 상단의 Add panels 버튼 왼쪽에 있는 톱니바퀴 아이콘을 선택합니다.
- 나타나는 UI 슬라이더에서 선형 플롯을 선택합니다
- 포인트 집계 섹션에서 랜덤 샘플링을 선택합니다