이 노트북은 대화형 노트북입니다. 로컬에서 실행하거나 아래 링크를 사용할 수 있습니다:
Chain of Density를 활용한 요약
Chain of Density 요약이란 무엇인가요?
- 초기 요약에서 시작합니다
- 핵심 정보를 유지하면서 더 간결해지도록 요약을 반복적으로 다듬습니다
- 반복할 때마다 Entities와 기술적 세부 정보의 밀도를 높입니다
왜 Weave를 사용하나요?
- LLM 파이프라인 추적: Weave를 사용해 요약 프로세스의 입력, 출력, 중간 단계를 자동으로 기록합니다.
- LLM 출력 평가: Weave의 기본 제공 도구를 사용해 요약 결과를 동일한 기준으로 엄밀하게 평가합니다.
- 조합 가능한 오퍼레이션 구축: 요약 파이프라인의 여러 부분에서 Weave 오퍼레이션을 조합하고 재사용합니다.
- 매끄럽게 통합: 기존 Python 코드에 Weave를 최소한의 오버헤드로 손쉽게 추가합니다.
환경 설정
Anthropic API 키를 발급받으려면:
- https://www.anthropic.com 에서 계정을 만드세요
- 계정 설정의 API 섹션으로 이동하세요
- 새 API 키를 생성하세요
- API 키를 .env 파일에 안전하게 저장하세요
weave.init(<project name>) 호출로 요약 작업용 새 Weave 프로젝트를 설정합니다.
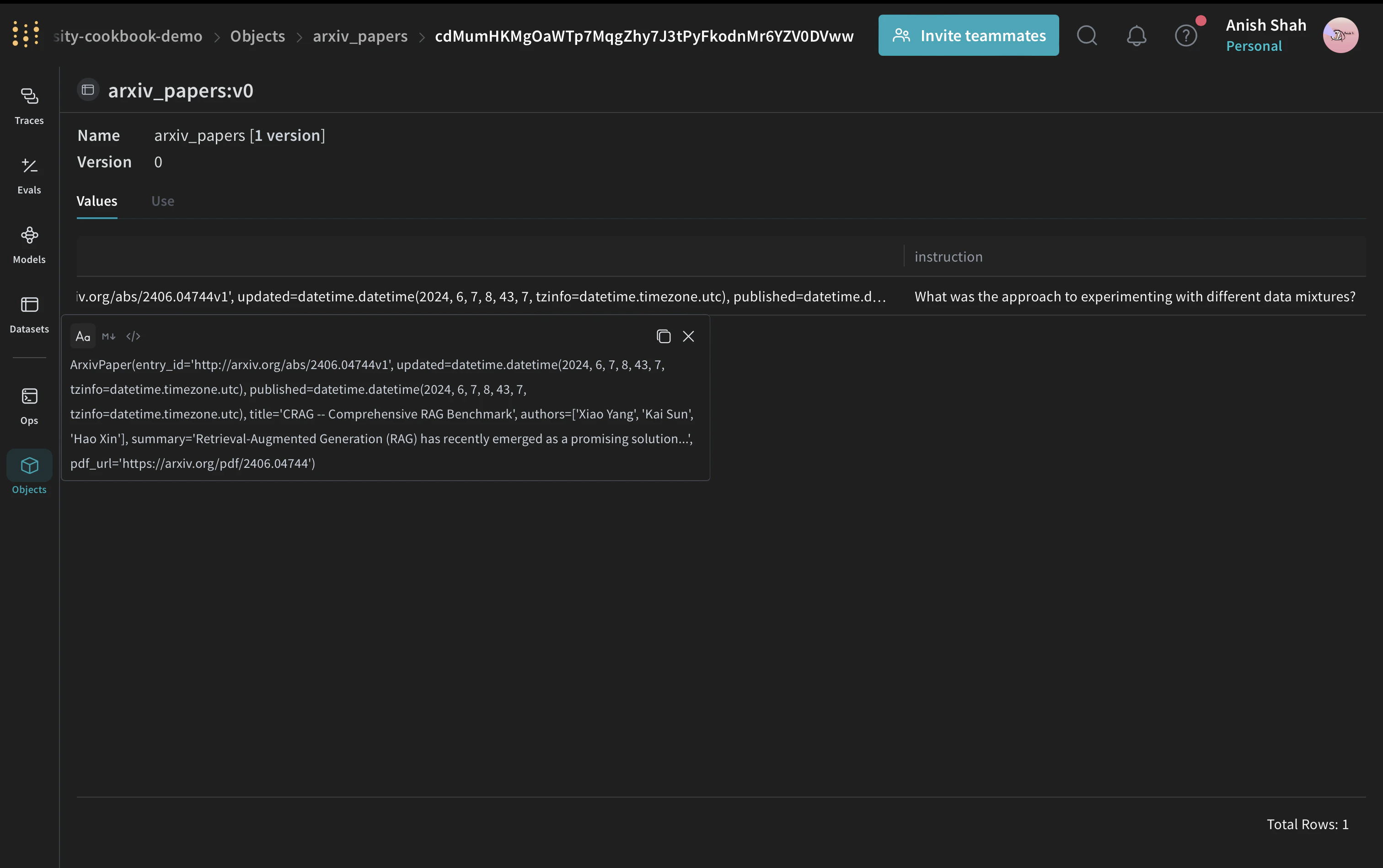
ArxivPaper 모델 정의
ArxivPaper 클래스를 만들겠습니다:
PDF 콘텐츠 불러오기
Chain of Density 요약 구현하기
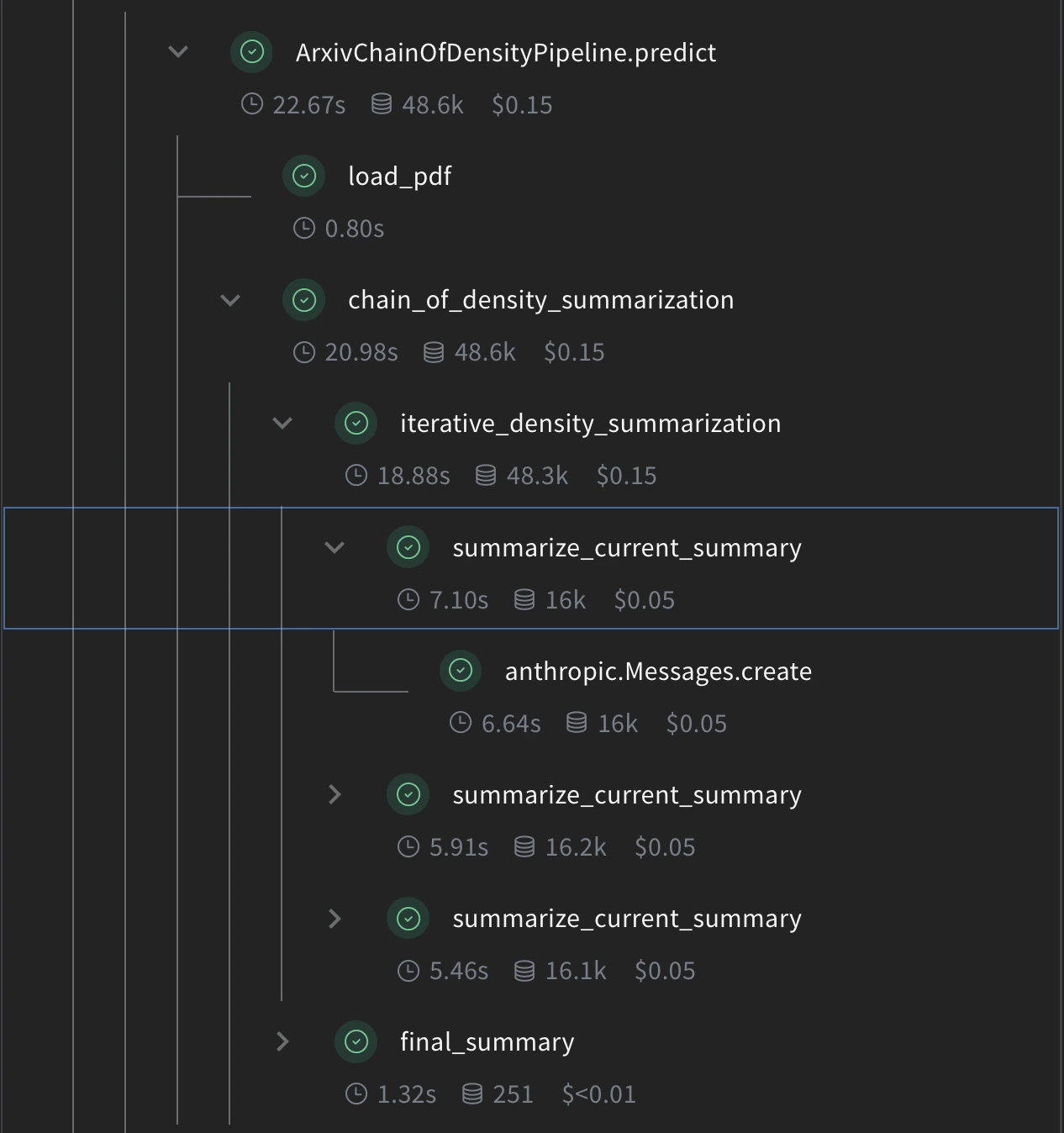
summarize_current_summary: 현재 상태를 바탕으로 단일 요약 단계를 생성합니다.iterative_density_summarization:summarize_current_summary를 여러 번 호출해 CoD 기법을 적용합니다.chain_of_density_summarization: 전체 요약 프로세스를 관리하고 결과를 반환합니다.
@weave.op() 데코레이터를 사용하면 Weave가 이러한 함수의 입력, 출력, 실행을 추적하도록 할 수 있습니다.
Weave Model 만들기
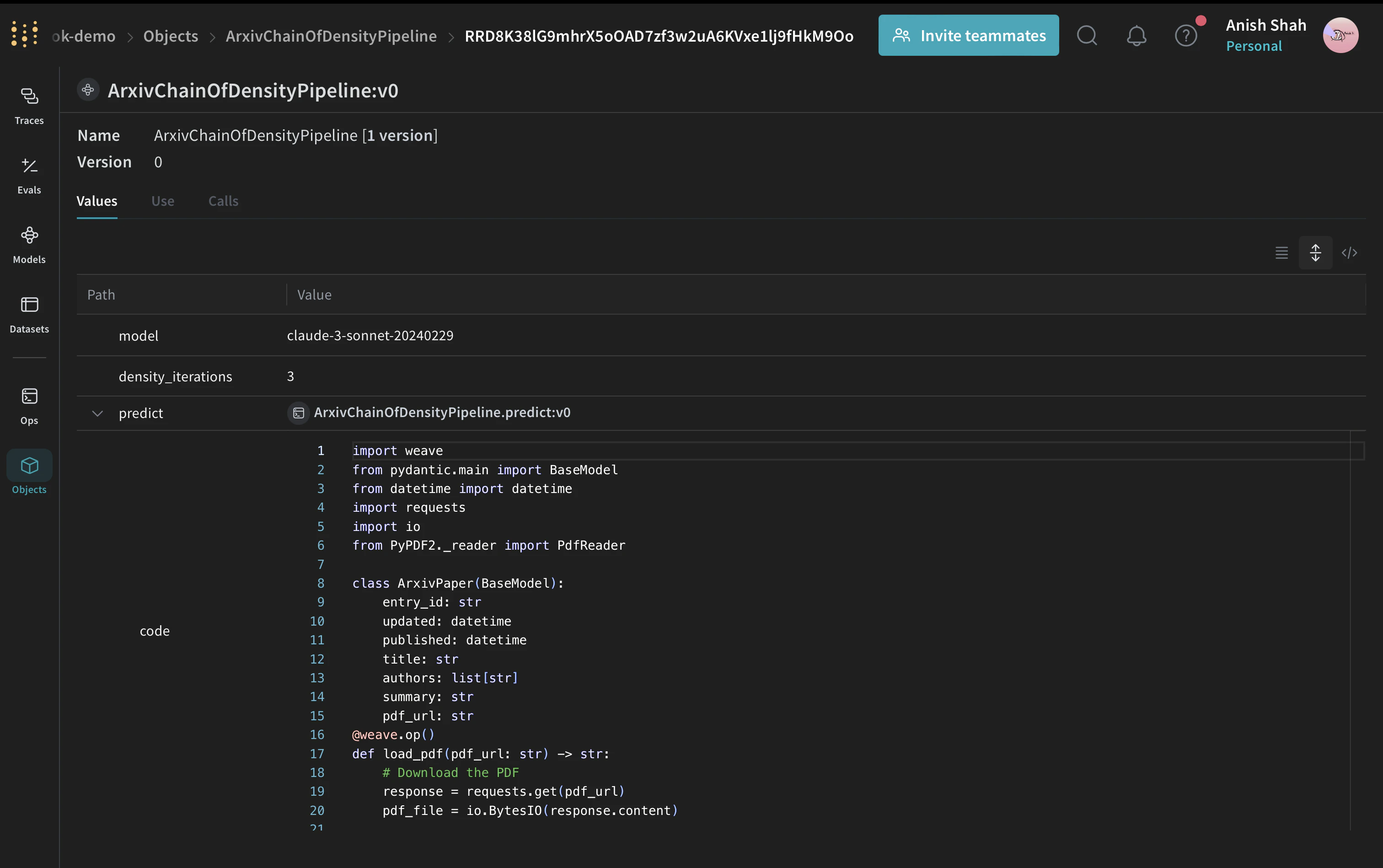
ArxivChainOfDensityPipeline 클래스는 요약 로직을 Weave Model로 캡슐화하며, 다음과 같은 주요 이점을 제공합니다:
- 자동 실험 추적: Weave는 모델의 각 실행에 대한 입력, 출력, 파라미터를 자동으로 캡처합니다.
- 버전 관리: 모델의 속성이나 코드 변경 사항이 자동으로 버전 관리되므로, 시간이 지남에 따라 요약 파이프라인이 어떻게 발전했는지 명확한 이력을 남길 수 있습니다.
- 재현성: 버전 관리와 추적 기능을 통해 요약 파이프라인의 이전 결과나 설정을 쉽게 재현할 수 있습니다.
- 하이퍼파라미터 관리:
model,density_iterations와 같은 모델 속성이 서로 다른 실행 전반에서 명확하게 정의되고 추적되므로 실험을 더 쉽게 수행할 수 있습니다. - Weave 에코시스템과의 인테그레이션:
weave.Model을 사용하면 evaluation 및 서빙 기능과 같은 다른 Weave 도구와 원활하게 인테그레이션할 수 있습니다.
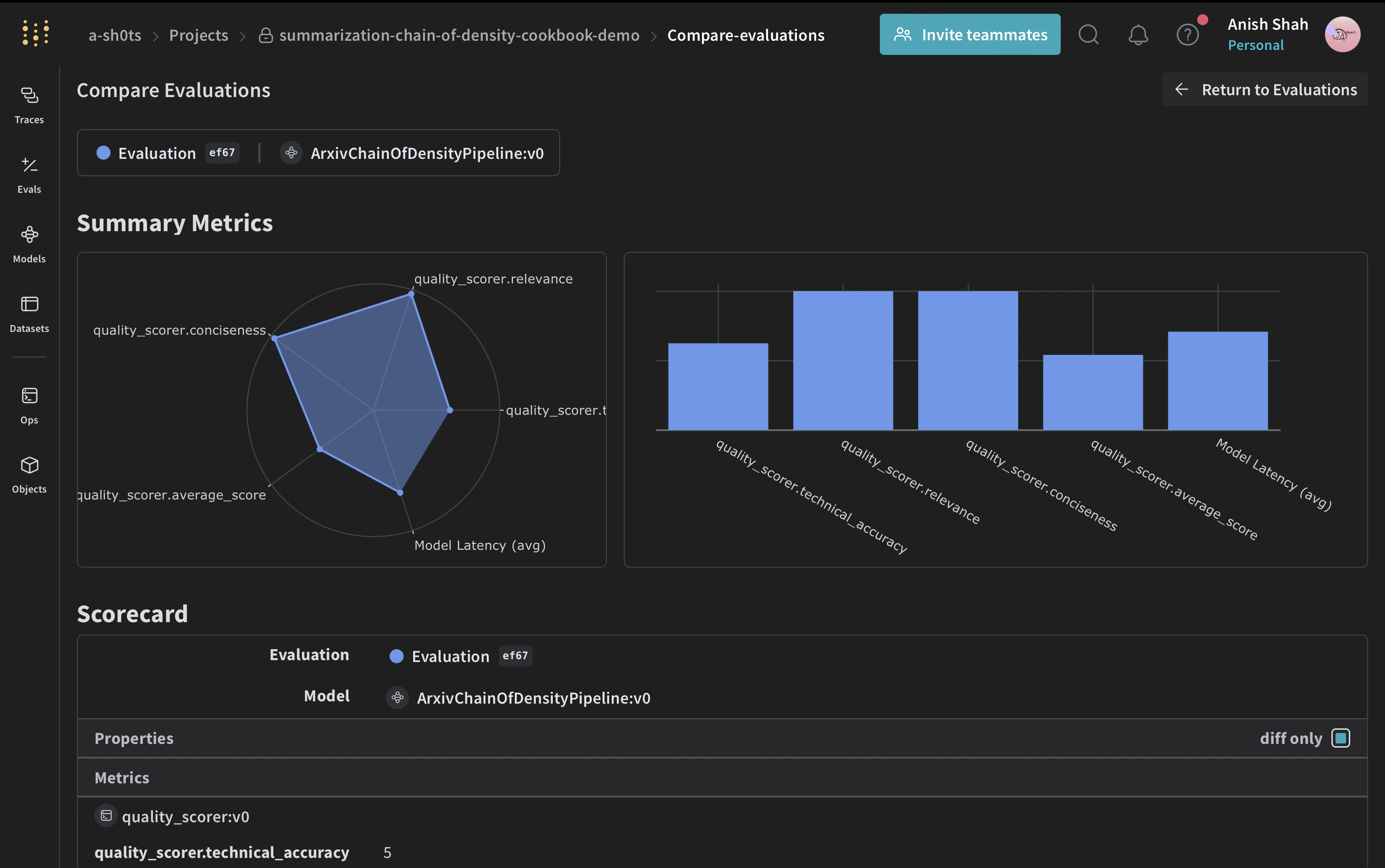
평가 메트릭 구현
Weave 데이터셋을 생성하고 평가를 실행하세요
결론
- 요약 프로세스의 각 단계에 대한 Weave 오퍼레이션 만들기
- 추적 및 평가를 쉽게 할 수 있도록 파이프라인을 Weave Model로 래핑하기
- Weave 오퍼레이션을 사용해 맞춤형 평가 메트릭 구현하기
- 데이터셋을 만들고 파이프라인 평가를 실행하기