- Python
- TypeScript
Weave에서 워크플로의 핵심은 _
Evaluation 객체_이며, 다음을 정의합니다:Evaluation을 정의하고 나면, 이를 Model 객체나 LLM 애플리케이션 로직을 포함한 맞춤형 함수에 대해 실행할 수 있습니다. .evaluate()를 호출할 때마다 _평가 run_이 시작됩니다. Evaluation 객체를 설계도라고 생각하면, 각 run은 해당 설정에서 애플리케이션이 얼마나 잘 동작하는지를 측정한 결과라고 볼 수 있습니다.1. Evaluation 객체 만들기
Evaluation 객체를 만드는 것은 평가 설정을 구성하는 첫 번째 step입니다. Evaluation은 예제 데이터, 점수 산정 로직, 그리고 선택적 전처리로 구성됩니다. 이후 이를 사용해 하나 이상의 평가를 실행합니다.
Weave는 각 예제를 애플리케이션에 전달한 뒤 여러 맞춤형 점수 함수로 출력 결과를 평가합니다. 이렇게 하면 애플리케이션의 성능을 확인할 수 있는 뷰와, 개별 출력과 점수를 자세히 살펴볼 수 있는 풍부한 UI를 활용할 수 있습니다.
(선택) 맞춤형 이름 지정
- Python
- TypeScript
평가 흐름에서는 맞춤 설정할 수 있는 이름이 두 가지 있습니다:
- Evaluation 객체 이름 (
evaluation_name): 설정한Evaluation객체에 대한 지속적으로 유지되는 레이블입니다. - Evaluation run 표시 이름 (
__weave["display_name"]): UI에 표시되는 특정 평가 실행의 레이블입니다.
Evaluation 객체 이름 지정
Evaluation 객체 자체의 이름을 지정하려면 Evaluation 클래스에 evaluation_name 매개변수를 전달하세요. 이 이름은 코드와 UI 목록에서 Evaluation을 파악하는 데 도움이 됩니다.개별 평가 run 이름 지정
특정 평가 run(evaluate() 호출)의 이름을 지정하려면 display_name이 포함된 __weave 딕셔너리를 사용하세요. 그러면 해당 run에 대해 UI에 표시되는 이름이 달라집니다.2. 테스트 예제용 데이터셋 정의
- Python
- TypeScript
다음 예제는 딕셔너리 목록으로 정의한 데이터셋을 보여줍니다:
3. 채점 함수를 정의합니다
Dataset의 각 예제에 점수를 매기는 데 사용됩니다.
- Python
- TypeScript
각 채점 함수에는 (선택) 맞춤형
일부 애플리케이션에서는 맞춤형
output 매개변수가 있어야 하며, 점수를 담은 딕셔너리를 반환해야 합니다. 필요하다면 예제의 다른 입력도 포함할 수 있습니다.채점 함수에는 output 키워드 인자가 필요하지만, 나머지 인자는 사용자가 정의하며 데이터셋 예제에서 가져옵니다. 인자 이름을 기준으로 딕셔너리 키를 매칭해 필요한 키만 사용합니다.다음 예제 scorer 함수 match_score1는 채점에 examples 딕셔너리의 expected 값을 사용합니다.(선택) 맞춤형 Scorer 클래스를 정의합니다
일부 애플리케이션에서는 맞춤형 Scorer 클래스를 만들고 싶을 수 있습니다. 예를 들어 특정 매개변수(예: chat model, prompt), 각 행에 대한 특정 채점 방식, 그리고 집계 점수의 특정 계산 방식을 갖춘 표준화된 LLMJudge 클래스를 만들 수 있습니다.자세한 내용은 RAG 애플리케이션의 모델 기반 Evaluation에서 Scorer 클래스를 정의하는 튜토리얼을 참조하세요.4. 평가할 모델 또는 함수 정의하기
- Python
- TypeScript
Model을 평가하려면 Evaluation으로 .evaluate()를 호출하세요. Models는 실험해 보고 Weave에서 캡처하려는 매개변수가 있을 때 사용합니다.predict를 실행하고, 각 채점 함수로 출력에 점수를 매깁니다.(선택 사항) 평가할 함수 정의하기
또는@weave.op()로 추적되는 맞춤형 함수를 평가할 수도 있습니다.5. 평가 실행
Evaluation 객체에서 .evaluate()를 호출합니다.
- Python
- TypeScript
evaluation이라는 Evaluation 객체와 평가할 model이라는 Model 객체가 있다고 가정하면, 다음 코드는 평가 run을 생성합니다.(선택) 여러 번 실행
각 예제를 여러 번 실행하려면Evaluation 객체에서 trials 파라미터를 설정할 수 있습니다.전체 평가 코드 예시
- Python
- TypeScript
다음 코드 샘플은 처음부터 끝까지 전체 평가 run 과정을 보여줍니다.
examples 딕셔너리는 prompt 값이 주어졌을 때 MyModel을 평가하는 데 match_score1 및 match_score2 Scorer 함수에서 사용되며, 맞춤형 함수 function_to_evaluate를 평가할 때도 사용됩니다. Model과 함수에 대한 평가는 모두 asyncio.run(evaluation.evaluate())로 호출합니다.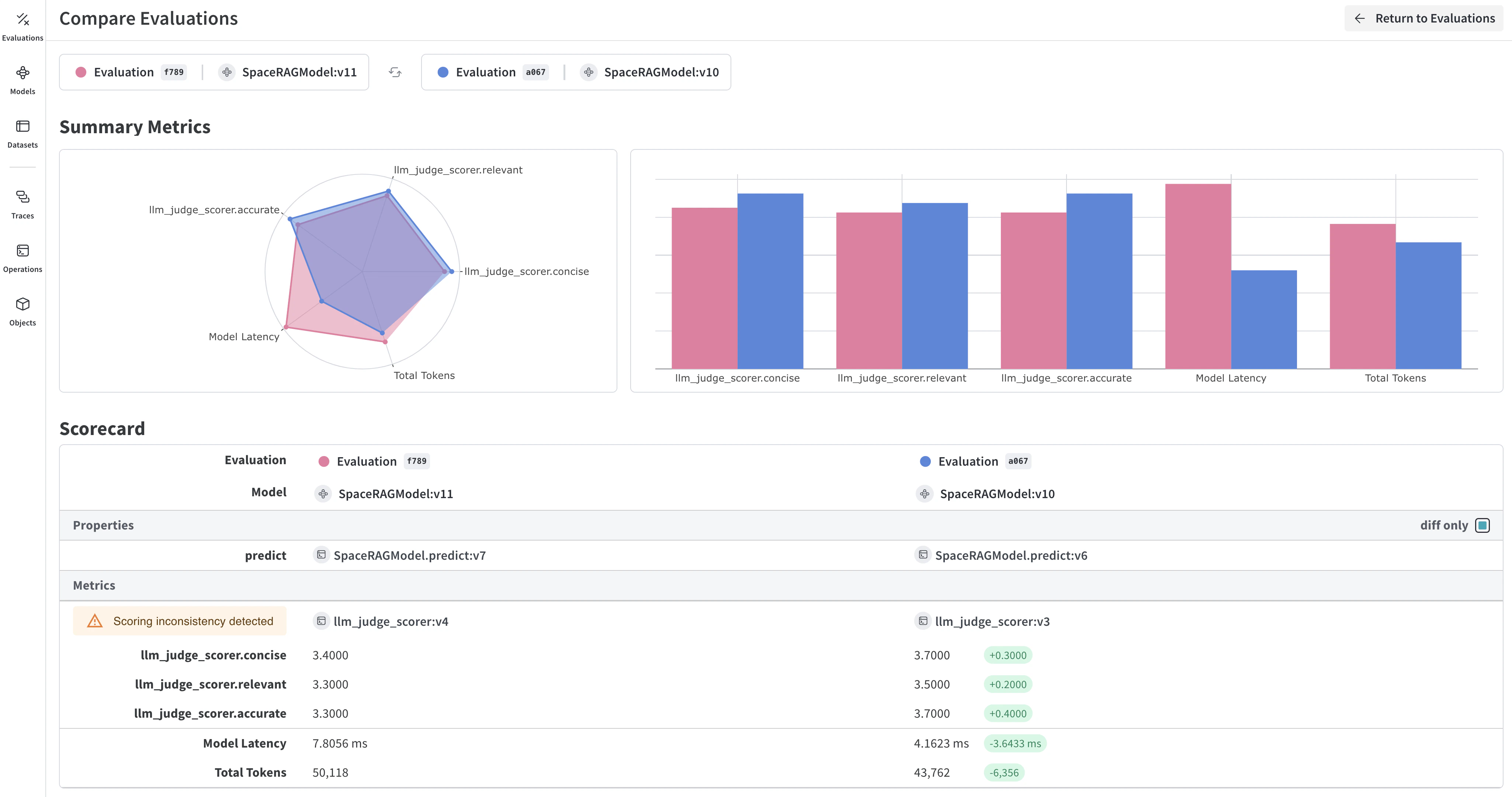
평가 고급 사용법
평가 전에 데이터셋 행 형식 맞추기
- Python
- TypeScript
preprocess_model_input 매개변수를 사용하면 데이터셋 예제가 평가 함수에 전달되기 전에 변환할 수 있습니다. 다음과 같은 경우에 유용합니다.- 모델이 기대하는 입력에 맞게 필드 이름 바꾸기
- 데이터를 올바른 형식으로 변환하기
- 필드 추가 또는 제거하기
- 각 예제에 대해 추가 데이터 불러오기
preprocess_model_input를 사용해 필드 이름을 바꾸는 방법을 보여주는 간단한 예제입니다.input_text 필드가 있는 예제가 들어 있지만, 평가 함수는 question 매개변수를 기대합니다. preprocess_example 함수는 필드 이름을 바꿔 각 예제를 변환하므로 평가가 올바르게 작동할 수 있습니다.전처리 함수는 다음과 같이 동작합니다.- 데이터셋에서 원본 예제를 받습니다
- 모델이 기대하는 필드가 포함된 딕셔너리를 반환합니다
- 각 예제가 평가 함수에 전달되기 전에 적용됩니다
평가에서 HuggingFace 데이터셋 사용하기
- Python
- TypeScript
서드파티 서비스 및 라이브러리와의 인테그레이션을 지속적으로 개선하고 있습니다.더 원활한 인테그레이션을 제공하기 위해 작업하는 동안, 현재는 Weave 평가에서 HuggingFace Datasets를 사용하기 위한 임시 우회 방법으로
preprocess_model_input을 사용할 수 있습니다.현재 방법은 평가에서 HuggingFace 데이터셋 사용 cookbook을 참조하세요.저장된 뷰
명령형 평가 (EvaluationLogger)
EvaluationLogger를 확인해 보세요. EvaluationLogger는 Python과 TypeScript 모두에서 사용할 수 있으며, 복잡한 워크플로에 더 유연하게 대응할 수 있습니다. 반면 표준 평가 프레임워크는 더 체계적인 구조와 가이드를 제공합니다.