시작하기
uv를 사용해 Verifiers 라이브러리를 설치하세요(라이브러리 작성자가 권장). 라이브러리를 설치하려면 다음 명령어 중 하나를 사용하세요:
롤아웃을 트레이스하고 평가하기
실험 추적 및 트레이스로 모델 파인튜닝하기
verifiers 저장소에는 시작하는 데 도움이 되는 즉시 실행 가능한 예제가 포함되어 있습니다.
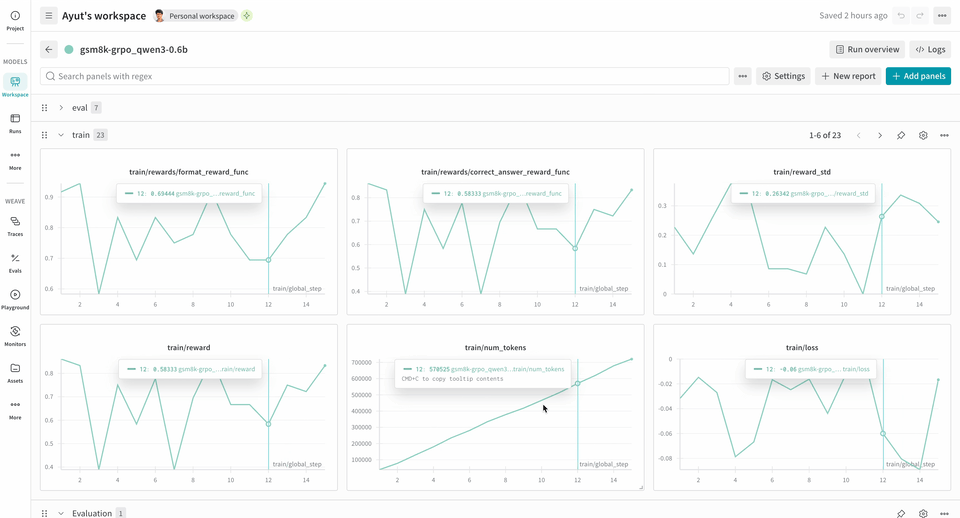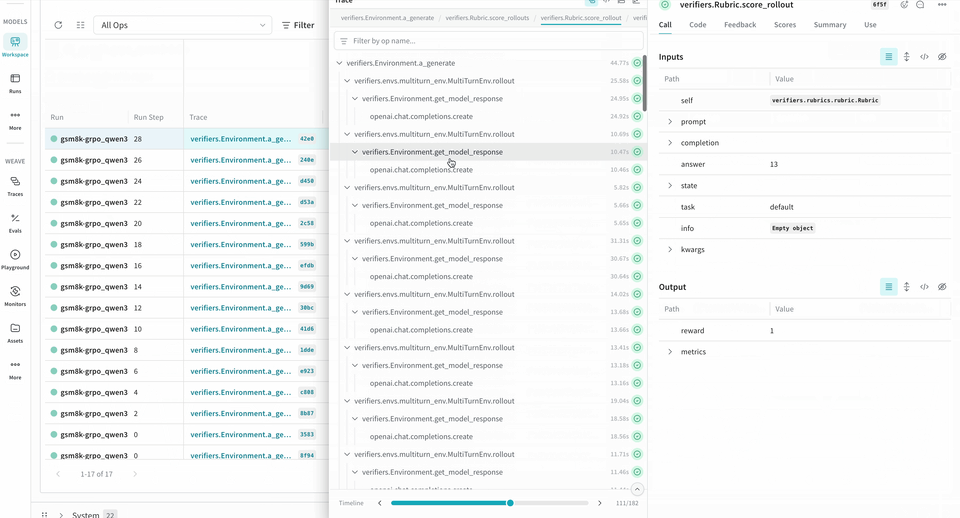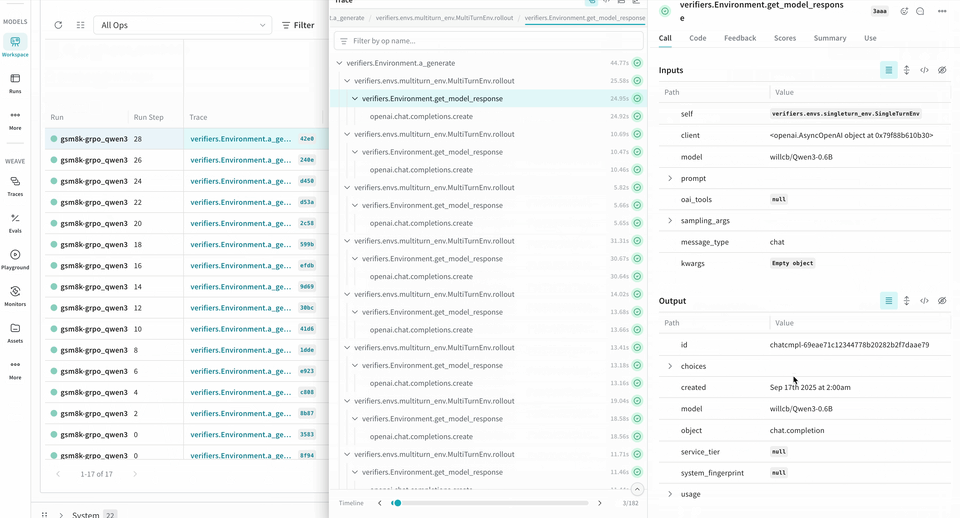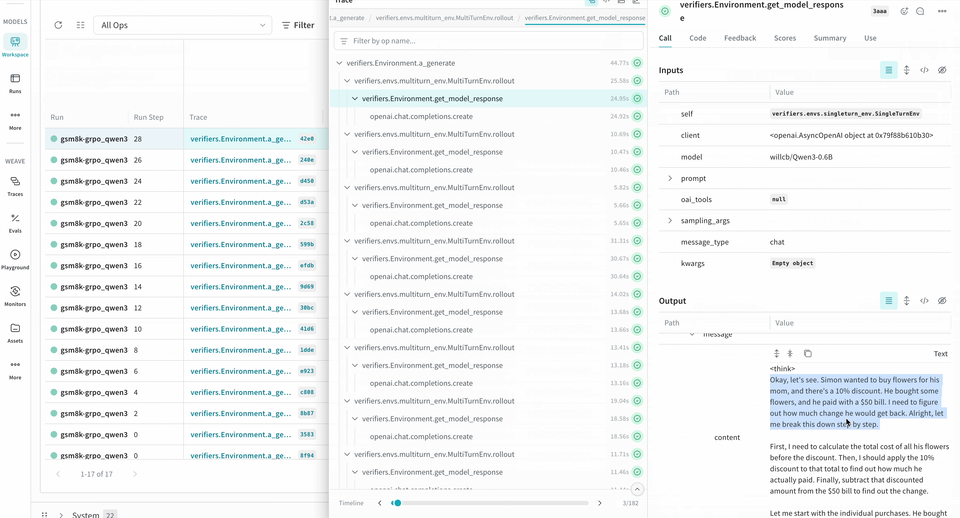
다음 예제 RL 트레이닝 파이프라인은 로컬 Inference 서버를 실행하고 GSM8K 데이터셋을 사용해 모델을 트레이닝합니다. 모델은 수학 문제에 대한 답을 생성하고, 트레이닝 루프는 출력을 채점한 뒤 그 결과에 따라 모델을 업데이트합니다. W&B는 loss, reward, accuracy와 같은 트레이닝 메트릭을 로깅하고, Weave는 입력, 출력, 추론 과정, 채점 내용을 캡처합니다.
이 파이프라인을 사용하려면:
- 소스에서 프레임워크를 설치합니다. 다음 명령어는 GitHub에서 Verifiers 라이브러리와 필요한 의존성을 설치합니다:
- 미리 준비된 환경을 설치합니다. 다음 명령어로 사전 구성된 GSM8K 트레이닝 환경을 설치합니다:
- 모델을 트레이닝하세요. 다음 명령어는 각각 Inference 서버와 트레이닝 루프를 시작합니다. 이 예제 워크플로는 기본적으로
report_to=wandb를 설정하므로wandb.init()을 별도로 호출할 필요가 없습니다. W&B에 메트릭을 로깅할 수 있도록 이 머신을 인증하라는 메시지가 표시됩니다.
이 예제는 H100 2개에서 성공적으로 테스트했으며, 안정성을 높이기 위해 다음 환경 변수를 설정했습니다.이 변수들은 디바이스 메모리 할당에 CUDA Unified Memory(CuMem)를 사용하지 않도록 합니다.
Environment.a_generate 및 Rubric.score_rollouts 메서드의 logprobs를 제외합니다. 이렇게 하면 트레이닝에 사용할 원본은 그대로 유지하면서도 페이로드 크기를 작게 유지할 수 있습니다.