- 단일 프로세스 추적: W&B로 rank 0 프로세스(“leader” 또는 “coordinator”라고도 함)를 추적합니다. 이는 PyTorch Distributed Data Parallel (DDP) 클래스로 분산 트레이닝 실험을 로깅할 때 흔히 사용하는 방법입니다.
- 여러 프로세스 추적: 여러 프로세스의 경우 다음 중 하나를 선택할 수 있습니다.
- 프로세스마다 하나의 run을 사용해 각 프로세스를 개별적으로 추적합니다. 필요하면 W&B App UI에서 이들을 함께 그룹화할 수 있습니다.
- 모든 프로세스를 하나의 run으로 추적합니다.
단일 프로세스 추적
wandb.init()으로 W&B run을 초기화하고, 실험 데이터를 해당 run에 wandb.Run.log()로 로깅합니다.
다음 샘플 Python 스크립트 (log-ddp.py)는 PyTorch DDP를 사용해 단일 머신의 두 GPU에서 메트릭을 추적하는 한 가지 방법을 보여줍니다. PyTorch DDP(torch.nn의 DistributedDataParallel)는 분산 트레이닝에 널리 사용되는 라이브러리입니다. 기본 원칙은 모든 분산 트레이닝 설정에 적용되지만, 구현 방식은 다를 수 있습니다.
Python 스크립트는 다음을 수행합니다:
torch.distributed.launch로 여러 프로세스를 시작합니다.--local_rank명령줄 인수로 rank를 확인합니다.- rank가 0으로 설정된 경우,
train()함수에서 조건부로wandb를 로깅하도록 설정합니다.
여러 프로세스 추적하기
- 각 프로세스마다 run을 생성해 각 프로세스를 개별적으로 추적합니다.
- 모든 프로세스를 단일 run으로 추적합니다.
각 프로세스를 개별적으로 추적하기
wandb.Run.finish()를 호출해 run이 완료되었음을 표시하세요.
여러 실험에 걸쳐 run을 추적하다 보면 관리가 어려울 수 있습니다. 이를 완화하려면 W&B를 초기화할 때(wandb.init(group='group-name')) group 파라미터에 값을 지정해 어떤 run이 특정 실험에 속하는지 추적하세요. 실험에서 트레이닝 및 평가 W&B Runs를 추적하는 방법에 대한 자세한 내용은 Group Runs를 참조하세요.
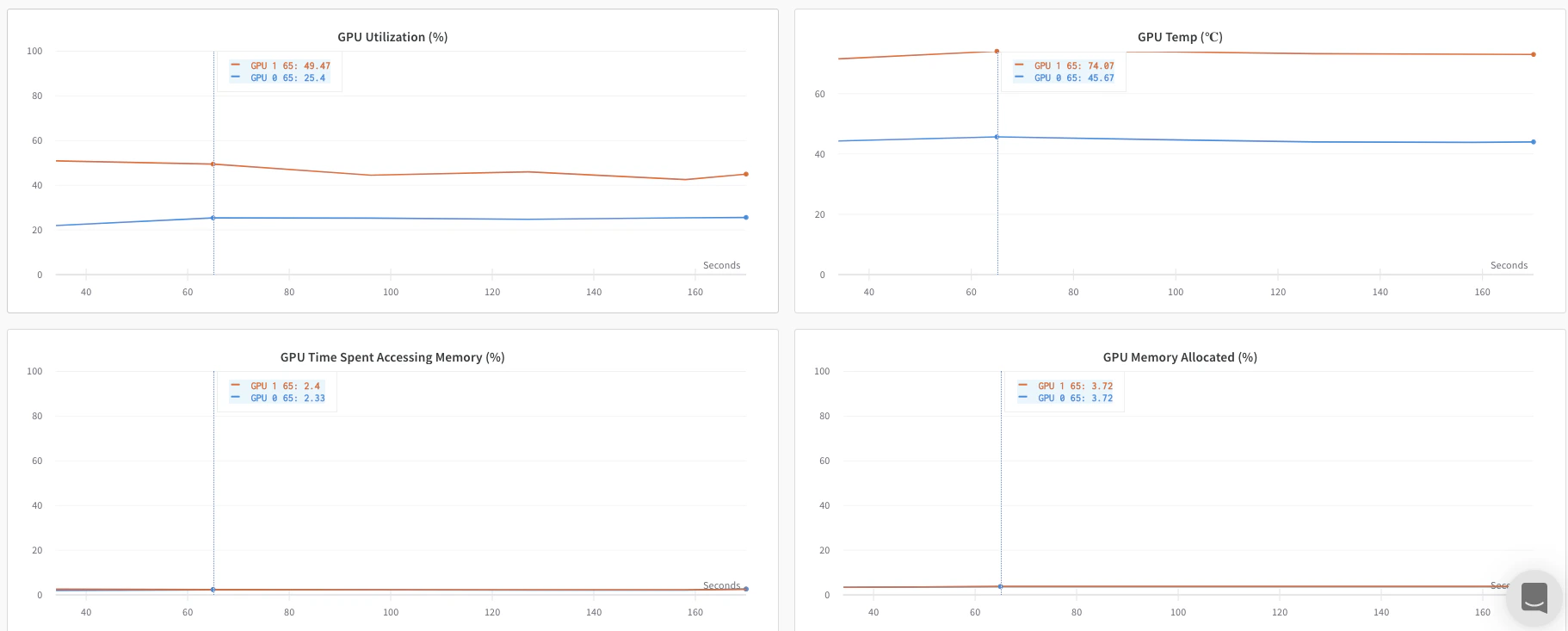
개별 프로세스의 메트릭을 추적하려는 경우 이 방식을 사용하세요. 일반적인 예로는 각 노드의 데이터와 예측(데이터 분포 디버깅용), 그리고 메인 노드 외부의 개별 배치 메트릭이 있습니다. 이 방식은 모든 노드의 시스템 메트릭을 가져오거나 메인 노드에서 사용할 수 있는 요약 통계를 얻기 위해 꼭 필요한 것은 아닙니다.
group 파라미터를 설정하는 방법을 보여줍니다:
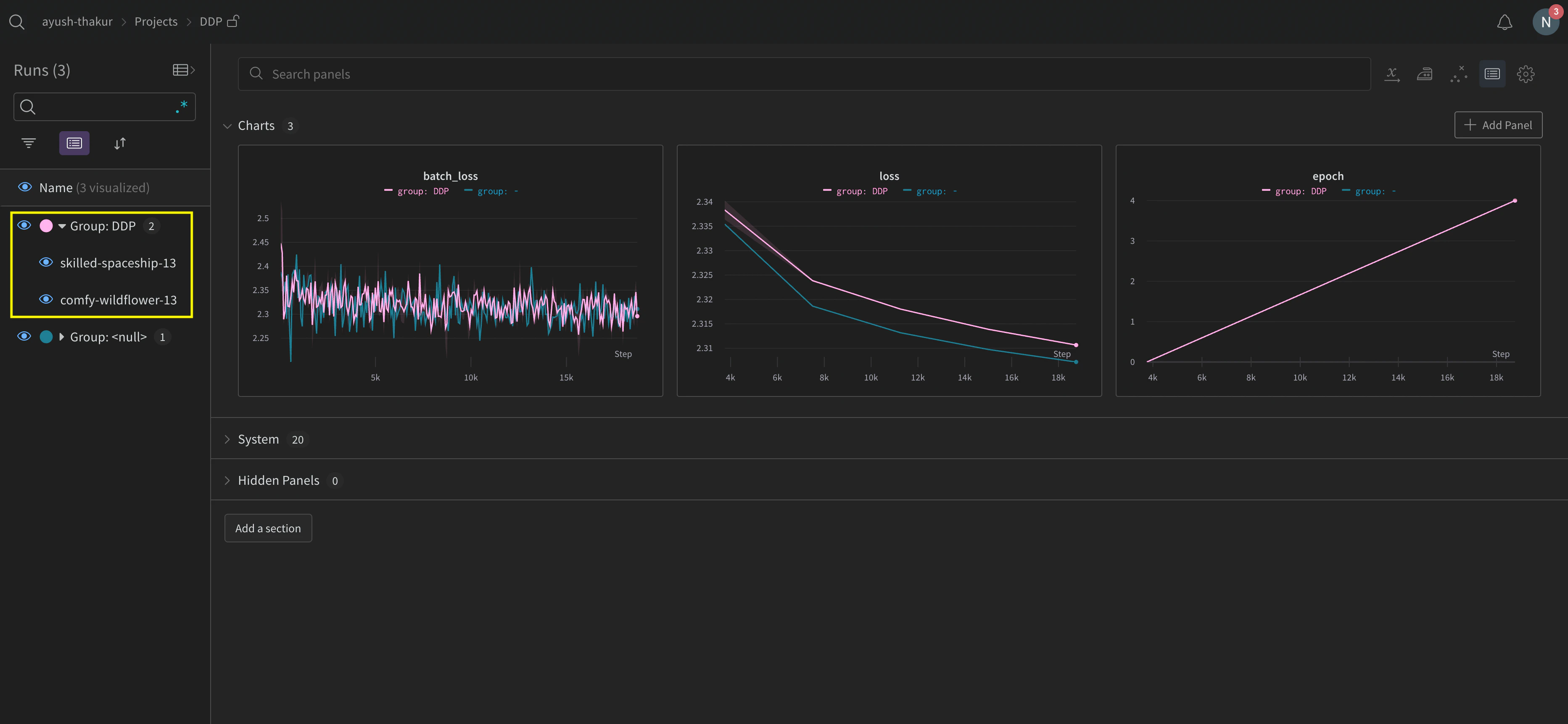
분산 run 정리
job_type 파라미터를 설정하세요(wandb.init(job_type='type-name')). 예를 들어, 메인 조정 노드 하나와 리포팅 워커 노드 여러 개가 있을 수 있습니다. 메인 조정 노드에는 job_type을 main으로, 리포팅 워커 노드에는 worker로 설정할 수 있습니다:
job_type을 설정한 후에는 워크스페이스에서 저장된 뷰를 만들어 run을 정리할 수 있습니다. 오른쪽 상단의 action () 메뉴를 클릭한 다음 Save as new view를 클릭합니다.
예를 들어, 다음과 같은 저장된 뷰를 만들 수 있습니다:
- 기본 뷰: 워커 노드를 필터링해 노이즈 줄이기
-
Filter를 클릭한 다음 Job Type을
worker로 설정합니다. - 리포팅 노드만 표시합니다
-
디버그 뷰: 문제 해결을 위해 워커 노드에 집중
- Filter를 클릭한 다음 Job Type을
==worker로 설정하고 State를INcrashed로 설정합니다. - 비정상 종료되었거나 오류 상태인 워커 노드만 표시합니다
- Filter를 클릭한 다음 Job Type을
-
모든 노드 뷰: 전체 노드를 함께 보기
- 필터 없음
- 전체적인 모니터링에 유용합니다
-
Filter를 클릭한 다음 Job Type을
모든 프로세스를 단일 run에 추적하기
Requirements여러 프로세스를 단일 run에 추적하려면 다음이 필요합니다.
-
W&B Python SDK
v0.19.9이상 - W&B Server v0.68 이상
wandb.init()으로 W&B run을 초기화합니다. settings 파라미터에 wandb.Settings 객체를 전달하고(wandb.init(settings=wandb.Settings()) 다음을 설정합니다.
- 공유 모드를 활성화하려면
mode파라미터를"shared"로 설정합니다. x_label에 고유한 레이블을 지정합니다.x_label에 지정한 값은 W&B App UI의 로깅과 시스템 메트릭에서 데이터가 어느 노드에서 왔는지 파악하는 데 사용됩니다. 지정하지 않으면 W&B가 호스트 이름과 임의의 해시를 사용해 레이블을 생성합니다.- 이 노드가 기본 노드임을 나타내려면
x_primary파라미터를True로 설정합니다. - 선택적으로 GPU 인덱스 목록([0,1,2])을
x_stats_gpu_device_ids에 전달해 W&B가 메트릭을 추적할 GPU를 지정할 수 있습니다. 목록을 제공하지 않으면 W&B는 머신의 모든 GPU에 대한 메트릭을 추적합니다.
x_primary=True는 기본 노드와 워커 노드를 구분합니다. 기본 노드만 설정 파일, 텔레메트리 등 노드 간에 공유되는 파일을 업로드합니다. 워커 노드는 이러한 파일을 업로드하지 않습니다.wandb.init()으로 W&B run을 초기화하고 다음을 제공합니다.
settings파라미터에wandb.Settings객체를 전달합니다(wandb.init(settings=wandb.Settings()). 포함할 항목은 다음과 같습니다.- 공유 모드를 활성화하려면
mode파라미터를"shared"로 설정합니다. x_label에 고유한 레이블을 지정합니다.x_label에 지정한 값은 W&B App UI의 로깅과 시스템 메트릭에서 데이터가 어느 노드에서 왔는지 파악하는 데 사용됩니다. 지정하지 않으면 W&B가 호스트 이름과 임의의 해시를 사용해 레이블을 생성합니다.- 이 노드가 워커 노드임을 나타내려면
x_primary파라미터를False로 설정합니다.
- 공유 모드를 활성화하려면
- 기본 노드가 사용한 run ID를
id파라미터에 전달합니다. - 선택적으로
x_update_finish_state를False로 설정합니다. 이렇게 하면 기본 노드가 아닌 노드가 run 상태를 너무 일찍finished로 업데이트하는 것을 방지하여, run 상태가 일관되게 유지되고 기본 노드에서 관리되도록 할 수 있습니다.
- 모든 노드에서 동일한 entity와 프로젝트를 사용하세요. 이렇게 하면 올바른 run ID를 찾는 데 도움이 됩니다.
- 각 워커 노드에서 기본 노드의 run ID를 설정하는 환경 변수를 정의하는 것도 좋습니다.
GKE의 멀티노드 및 멀티 GPU Kubernetes 클러스터에서 모델을 트레이닝하는 방법에 대한 엔드 투 엔드 예시는 Distributed Training with Shared Mode report를 참조하세요.
- run이 포함된 프로젝트로 이동합니다.
- 프로젝트 사이드바에서 Runs 탭을 클릭합니다.
- 보려는 run을 클릭합니다.
- 프로젝트 사이드바에서 Logs 탭을 클릭합니다.
x_label에 지정한 레이블을 기준으로 콘솔 로그를 필터링할 수 있습니다. 예를 들어, 다음 이미지는 rank0, rank1, rank2, rank3, rank4, rank5, rank6 값을 x_label에 제공한 경우 콘솔 로그를 필터링할 때 사용할 수 있는 옵션을 보여줍니다.
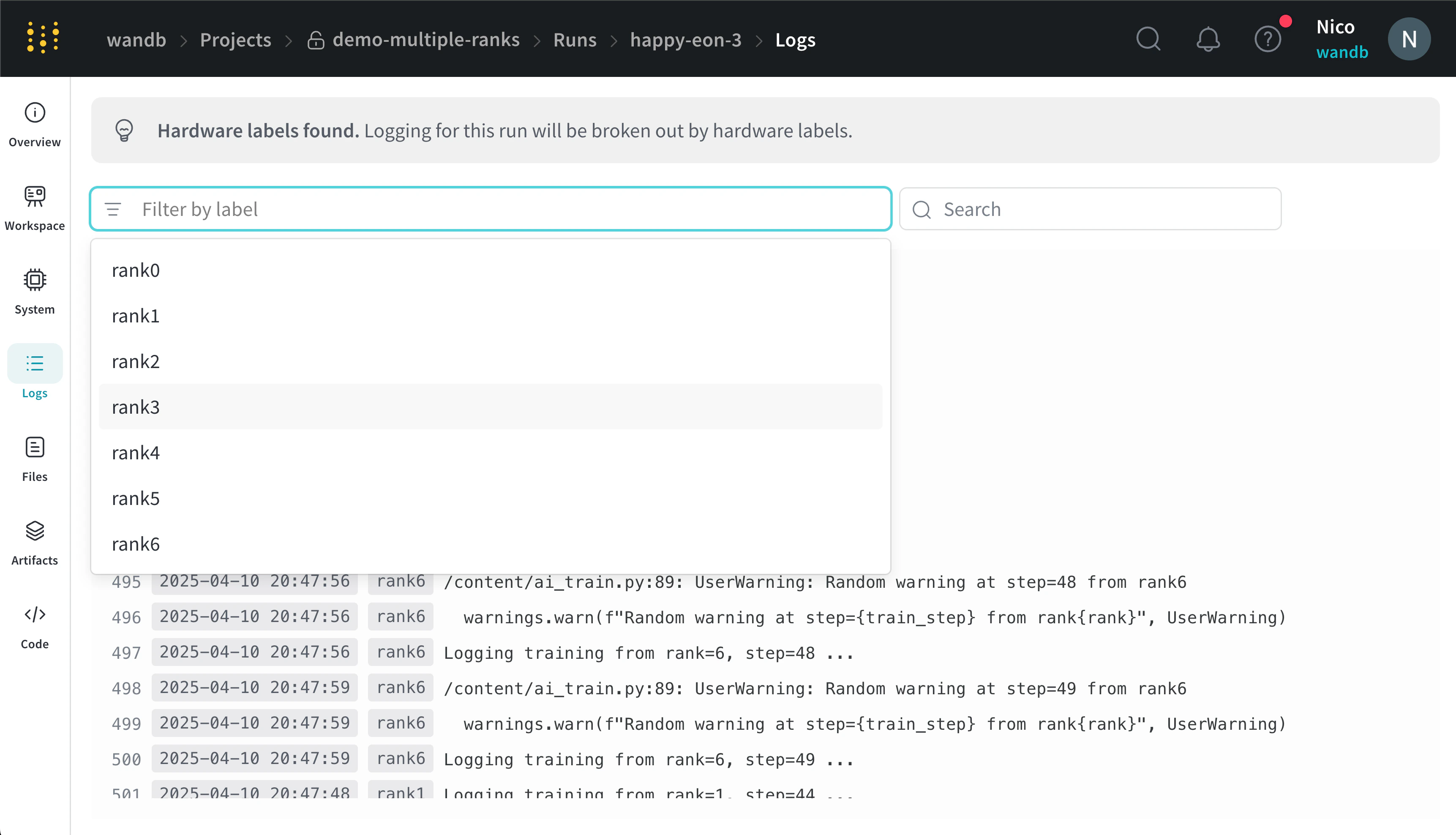
x_label 매개변수로 지정한 고유한 레이블(rank_0, rank_1, rank_2)이 있습니다.
사용 사례 예시
프로세스 생성
wandb.setup()를 사용하세요:
문제 해결
- 트레이닝 시작 시 멈춤 -
wandb의 멀티프로세싱이 분산 트레이닝의 멀티프로세싱과 간섭하면wandb프로세스가 멈출 수 있습니다. - 트레이닝 종료 시 멈춤 -
wandb프로세스가 언제 종료되어야 하는지 알지 못하면 트레이닝 작업이 멈출 수 있습니다. Python 스크립트 끝에서wandb.Run.finish()API를 호출해 W&B에 run이 종료되었음을 알려주세요.wandb.Run.finish()API는 데이터 업로드를 완료하고 W&B를 종료합니다. W&B는 분산 작업의 안정성을 높이기 위해wandb service명령어를 사용할 것을 권장합니다. 앞서 설명한 두 가지 트레이닝 문제는 모두 wandb service를 사용할 수 없는 버전의 W&B SDK에서 흔히 발생합니다.
W&B Service 활성화
W&B SDK 0.13.0 이상
0.13.0 이상 버전에서는 W&B Service가 기본적으로 활성화됩니다.
W&B SDK 0.12.5 이상
wandb.require() 방법을 사용하고, 메인 함수 내에 문자열 "service"를 전달하세요:
WANDB_START_METHOD 환경 변수를 "thread"로 설정하세요.