weave.init()를 호출하면 Weave가 ChatNVIDIA 라이브러리를 통해 이루어지는 LLM call을 자동으로 추적하고 로그합니다.
트레이싱
- Python
- TypeScript
Weave는 ChatNVIDIA Python 라이브러리의 트레이스를 자동으로 캡처할 수 있습니다.원하는 프로젝트 이름으로
weave.init(<project-name>)을 호출해 캡처를 시작하세요.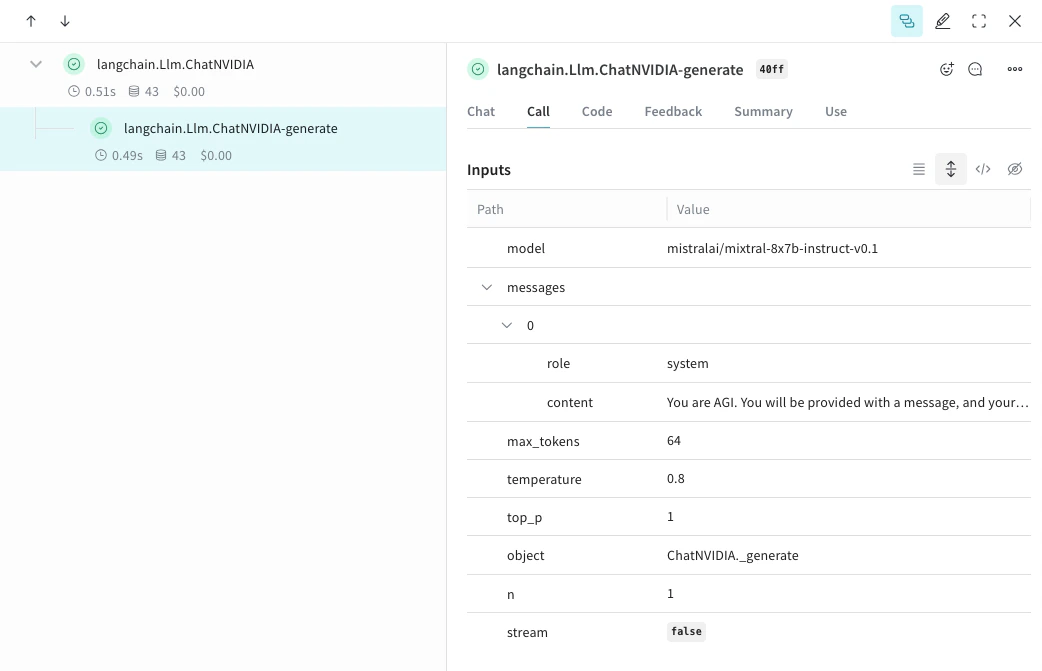
직접 ops 추적하기
- Python
- TypeScript
함수를 Weave로 이동한 다음 UI에서
@weave.op으로 래핑하면 입력, 출력, 앱 로직 캡처가 시작되어 데이터가 앱 전반에서 어떻게 흐르는지 디버그할 수 있습니다. ops를 깊이 중첩하고 추적하려는 함수의 트리를 구성할 수 있습니다. 또한 실험하는 동안 코드 버전 관리도 자동으로 시작되어 git에 커밋되지 않은 임시 세부 정보까지 캡처할 수 있습니다.ChatNVIDIA Python 라이브러리를 호출하는 @weave.op 데코레이터가 적용된 함수만 만들면 됩니다.아래 예시에는 op로 래핑된 함수가 2개 있습니다. 이렇게 하면 RAG 앱의 retrieval step 같은 중간 step이 앱 동작에 어떤 영향을 미치는지 확인하는 데 도움이 됩니다.get_pokemon_data를 클릭하면 해당 step의 입력과 출력을 확인할 수 있습니다.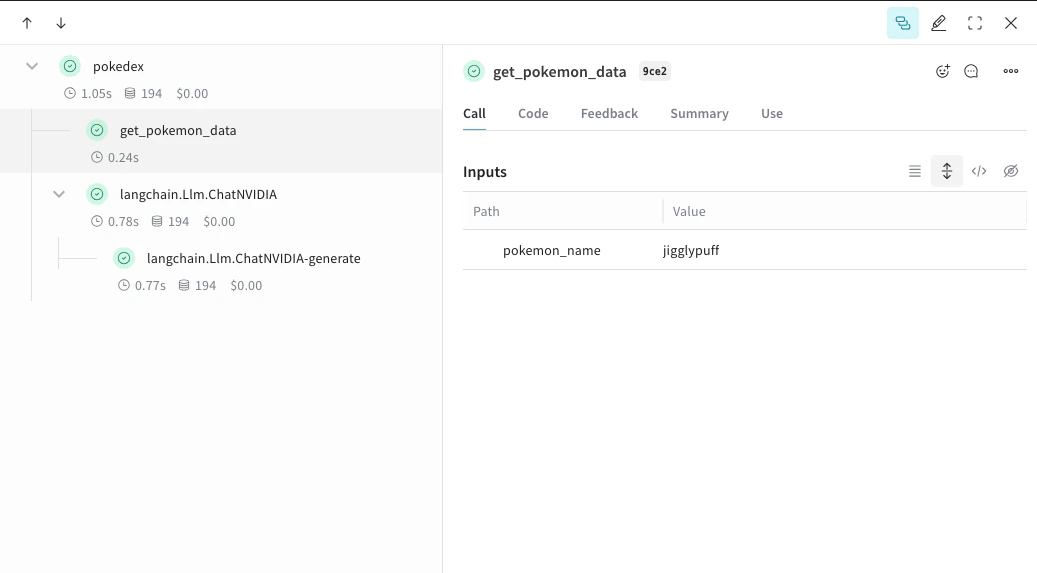
더 쉽게 실험할 수 있도록 Model 만들기
- Python
- TypeScript
구성 요소가 많아지면 실험을 체계적으로 정리하기가 어렵습니다.
Model 클래스를 사용하면 시스템 프롬프트나 사용 중인 모델처럼 앱의 실험 관련 세부 사항을 포착하고 정리할 수 있습니다. 이렇게 하면 앱의 다양한 반복 버전을 정리하고 비교하는 데 도움이 됩니다.Model은 코드 버전 관리와 입력/출력 포착에 더해, 애플리케이션의 동작을 제어하는 구조화된 매개변수도 포착하므로 어떤 매개변수가 가장 잘 작동했는지 쉽게 찾을 수 있습니다. 또한 Weave Models를 serve 및 Evaluations와 함께 사용할 수도 있습니다.아래 예시에서는 model과 system_message를 바꿔 가며 실험할 수 있습니다. 이 둘 중 하나를 변경할 때마다 GrammarCorrectorModel의 새 version 이 생성됩니다.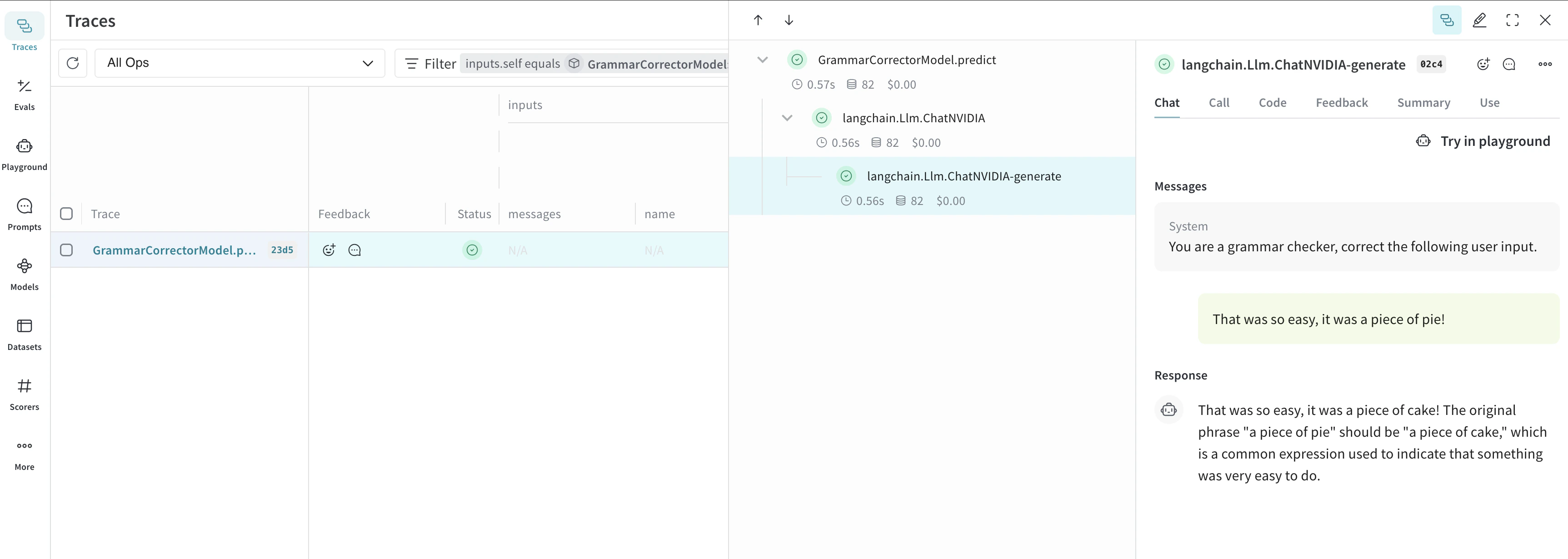
사용 정보
invoke, stream 및 해당 비동기 버전을 지원합니다. 또한 도구 사용도 지원합니다.
ChatNVIDIA는 여러 유형의 모델과 함께 사용하도록 설계되었기 때문에 함수 호출은 지원하지 않습니다.